
The![]() Developer Platform
Developer Platform
Modern backends sprawl into a mix of databases, queues, workers, and glue code. That fragmentation slows development and complicates operations. Rama replaces that whole stack with a unified, fault-tolerant programming model that scales from one node to thousands.

LESS CODE FOR LARGE-SCALE BACKENDS
Building and managing large-scale backends involves juggling numerous tools for storage, computation, deployment, and coordination. Worse, custom tools frequently need to be built from scratch for specialized storage or computation needs.
By being a unified platform, Rama drastically reduces the amount of infrastructure needed. Additionally, it eliminates the need to build custom infrastructure since its simple building blocks can be composed in innumerable ways to satisfy any storage or computation use case.
For an example of this cost reduction, see our complete reimplementation of Mastodon to be Twitter-scale in 100x less code than Twitter wrote to build the equivalent.

REDUCED INFRASTRUCTURE COMPLEXITY
Since Rama can build an entire backend with diverse needs on its own, the amount of infrastructure needed is greatly decreased.
Rather than operate multiple databases, distributed processors, background queues, orchestration frameworks, and more, you only need Rama. But if you need to integrate with any other infrastructure, Rama makes that easy too.
This greatly simplifies productionizing an application, as deploying, updating, and scaling applications are just one-line CLI commands.
See our post Rama in five minutes for an example of how a stack that normally requires Postgres, Kafka, Memcached, background workers, and glue code can be expressed as a single Rama application.

LESS GLUE CODE
Glue code takes many forms, such as ORMs to translate objects to database schemas, serialization between systems, cache invalidation logic, and retry and backoff handling at every system boundary.
Rama eliminates most of this. Logs, compute, and storage are integrated so data flows through without translation. Transactions span the entire module without coordination code. Datastores are composable data structures that match your application, so you store domain data directly.
This elimination of glue code reduces the code needed to build an application substantially, which is why Rama is so good for small-scale applications as well.

Free consultation
Schedule a free 45-minute consultation to discuss your use cases, ask questions, or even pair program on using Rama to solve your problem.
Schedule
Rama's programming model eliminates the need to use multiple databases, operate background queues, have a separate stream processing system, or deploy custom workers. Rama can build highly interactive consumer applications, large-scale analytics systems, transactional applications, recommendation engines, or anything you can imagine.
Since Rama is programmed entirely with Java, Clojure, or any other JVM language – and not a custom DSL – you're never restricted in what you can do or your ability to decompose logic.
A single Rama cluster can host any number of applications on it. Deploying, updating, and scaling Rama applications are one-line CLI commands.
See short, self-contained, thoroughly commented examples of using Rama in the rama-demo-gallery repository.
Unlike a database, which implements a fixed data model (e.g. relational, key/value, document, graph), datastores you materialize with Rama can be any shape. These datastores, called PStates, are defined in terms of the simpler building block of data structures (e.g. maps, sets, lists). A data model is just a particular combination of data structures. Because PStates can be any combination of data structures, they can implement infinite data models.
Databases force an application to conform to its data model even if that data model is suboptimal for all use cases. Programming Rama applications revolves around materializing as many PStates as needed, with each PState shaped as the optimal data model for the use cases it supports.
PStates are durable and incrementally replicated, making them suitable for any use case for which databases are used. Any types can be stored in PStates, allowing you to represent data your way rather than being restricted by the types allowed by a database. Rama makes it easy to materialize any number of PStates of any number of shapes, all updated incrementally.

Relational databases require you to configure isolation levels to balance performance with the exact semantics you get on a transaction. Isolation levels can be difficult to reason about. Rama provides ACID semantics as strong as any database, but you never need to specify isolation levels. Instead, because Rama colocates computation and storage it gives optimal performance and ideal semantics for each context automatically.
Rama has very strong transactional capabilities from colocating computation and storage. When processing data using microbatch topologies, all writes to all views are always a cross-partition transaction.

Rama applications are programmed with any JVM language, with first-class Java and Clojure APIs available. Because Rama is programmed as a library instead of a DSL, there's no limitations on what you can code, how you organize your code, and how you decompose your logic. You can use any Java or Clojure library, and you can use and store any type.
Rama's dataflow-based API can do the same things SQL can do, while also able to seamlessly intermix regular Java or Clojure code. Views are read and written to with a powerful "path"-based API.
Clients to Rama applications written in a JVM language can use Rama's native Java or Clojure APIs, and clients from other languages can use Rama's REST API to do reads/writes with HTTP.

In a set of benchmarks against MongoDB and Cassandra, Rama matched or exceeded their performance in every case. To demonstrate Rama's performance and scalability on a real application, we rebuilt Mastodon from scratch and ran it at Twitter-scale with 100M bots posting 3,500 times per second on an extremely unbalanced social graph. The performance of the Rama-based implementation was slightly better than Twitter's published performance numbers while being 100x less code.
Rama being a heavily integrated system means many sources of performance overhead in traditional systems don't exist in Rama, such as process and network boundaries between components. Computation and storage being colocated in Rama are big reasons why its performance numbers are so good.

Rama provides a new capability called "fine-grained reactivity". Traditional databases only support coarse-grained reactivity, like telling you a row changed without saying precisely what changed. In other systems, fine-grained information is provided in limited cases or for limited types of views/queries.
Rama's reactive queries can be done at any level of any view, no matter how complicated the structure, and when Rama detects a change it sends minimal diffs saying precisely what changed (like "to the subscribed set elements A and D were added and element F was removed"). At no point is a full diff computed between old and new versions of the value, as other systems do.
Clients can consume the incrementally updated value as it changes, or they can tap into the stream of diffs being sent by Rama.
Rama can easily be integrated with any other system, such as databases (e.g. Postgres, Cassandra, MongoDB), queues (e.g. Kafka, Kinesis, EventHub), monitoring systems (e.g. Datadog, Grafana), or anything else. The ease of integration makes it easy to add Rama incrementally to an existing backend.
Rama being an integrated system greatly simplifies the deployment and management of applications in production. Launching, updating, and scaling Rama applications, called modules, are one-line commands at the terminal. Rather than writing custom scripts to orchestrate updates across multiple components, as is typical with traditional architectures, Rama has built-in, fault-tolerant routines for end-to-end deployment of Rama modules.
Here is an example of launching a module:
rama deploy --action launch --jar target/my-application-1.0.0.jar --module com.mycompany.MyModule --tasks 64 --threads 16 --workers 8 --replicationFactor 3
Updates to modules can change any aspect of them, including updating logic or adding new views. Here's an example of updating a module:
rama deploy --action update --jar myapplication-1.1.0.jar --module com.mycompany.MyModule
Finally, here's an example of scaling a module by adding resources:
rama scaleExecutors --module com.mycompany.MyModule --threads 32 --workers 16
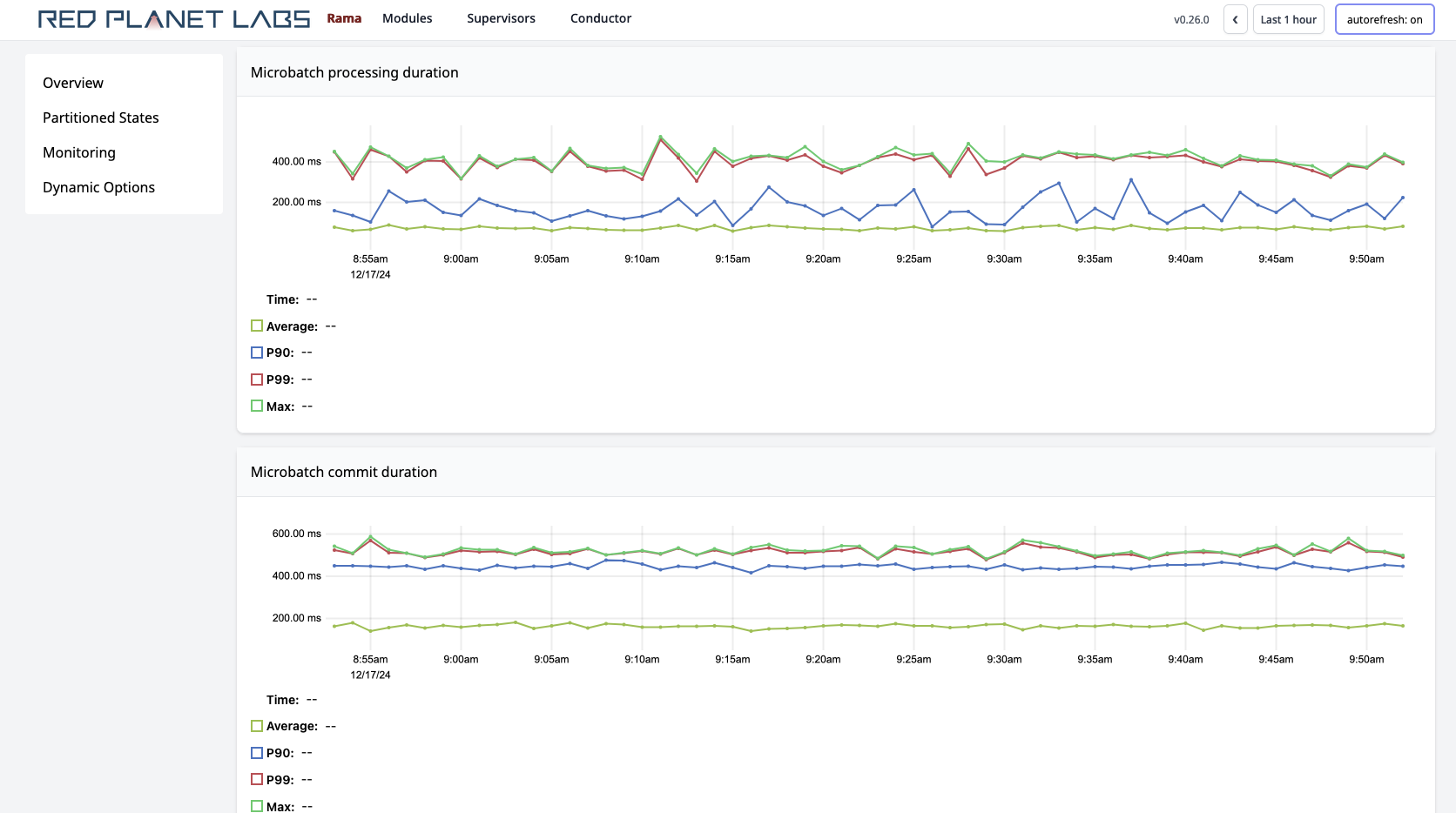
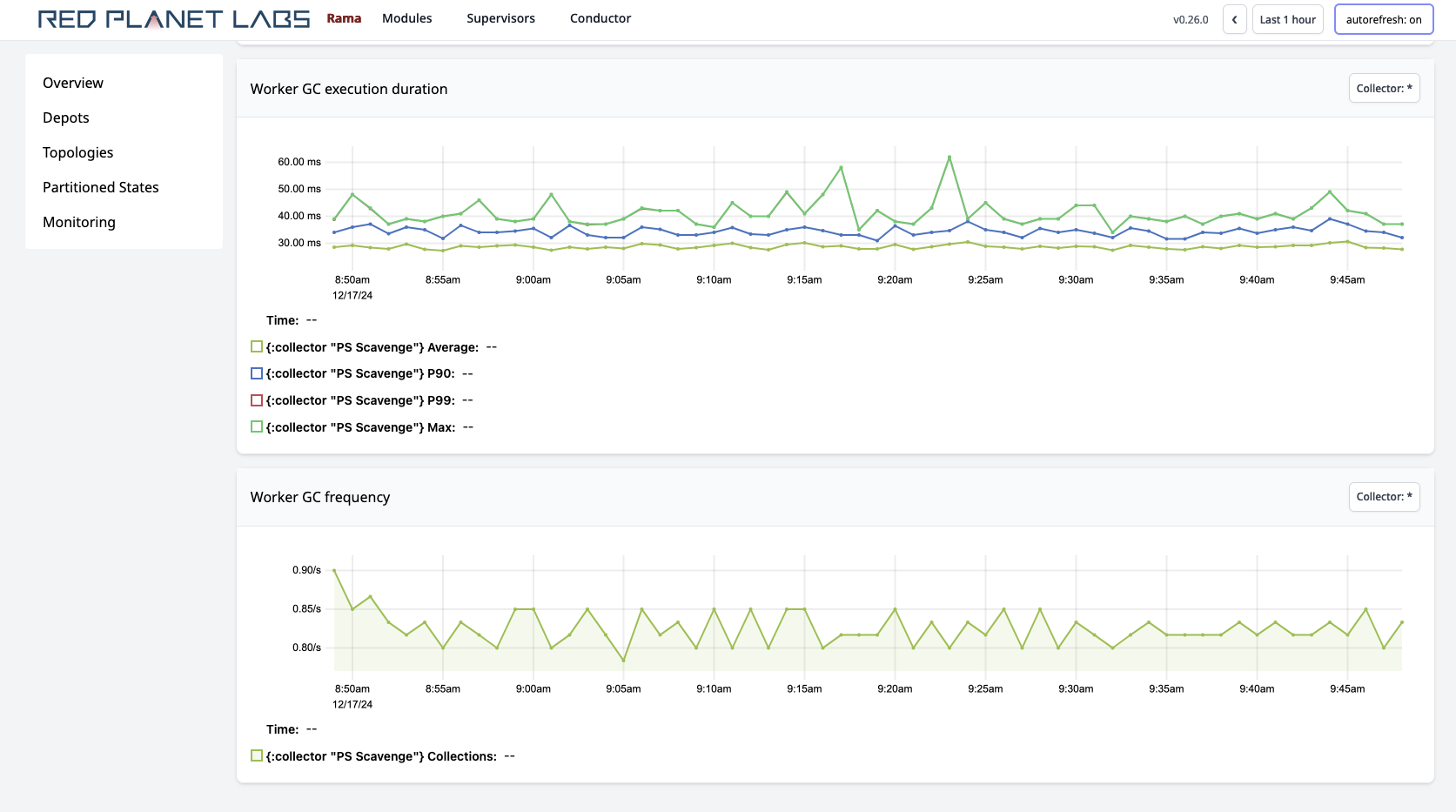
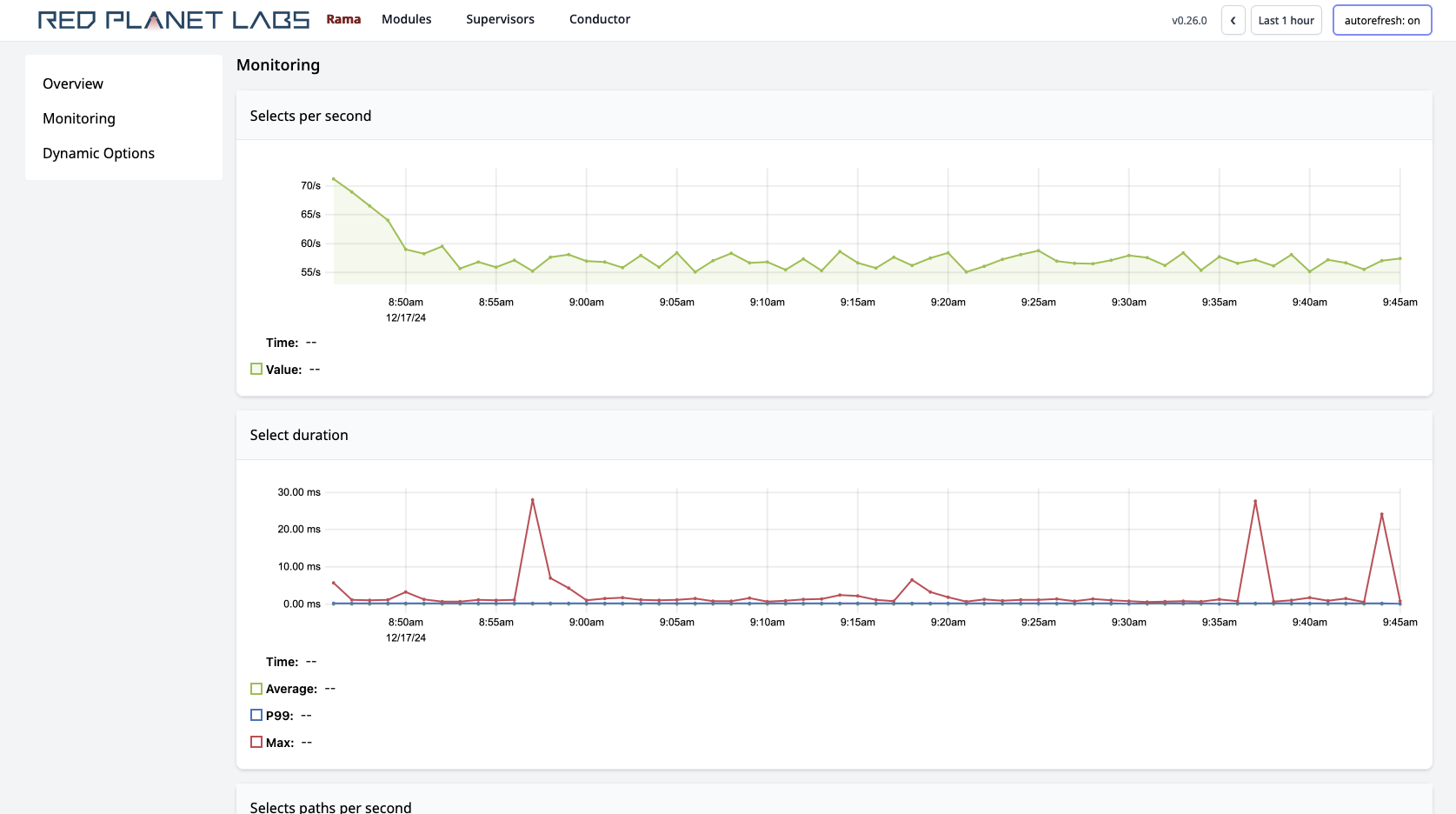
Rama provides detailed telemetry on all Rama applications out of the box, viewable with its web-based Cluster UI. All aspects of Rama applications are measured, aggregated, and displayed in time-series charts: latency/throughput distributions for reads, load of task threads, memory/GC telemetry, event throughputs/latencies categorized by type, and many more.
Rama uses itself to implement telemetry, implementing data ingestion, processing, indexing, and queries via a regular Rama module. All telemetry can be exported to external monitoring systems by either querying the aggregated stats via an HTTP API, or consuming the raw data directly from the monitoring module.

Rama is free to use up to two nodes, which is sufficient for running small or medium-scale applications in production. Download at this page. We have one-click deploys available for Rama clusters for AWS or Azure.
Rama can be experimented with locally in a simulated in-process environment with a Maven dependency. Check out the open-source rama-demo-gallery for a project configured to use that dependency with many thoroughly commented examples of using Rama. Here are the commands to download and run all examples from that project:
git clone https://github.com/redplanetlabs/rama-demo-gallery.git
mvn test
git clone https://github.com/redplanetlabs/rama-demo-gallery.git
lein test
See the pricing page for details on larger clusters or accessing enterprise features.
BUILD ANYTHING

SOCIAL NETWORK

WEB ANALYTICS

BANKING APPLICATION

RECOMMENDATION ENGINE

AUCTION APPLICATION

GRAPH SEARCH

TEXT-BASED SEARCH ENGINE

E-COMMERCE

LOG ANALYTICS
Or anything you can imagine.
CONSULT WITH AN EXPERT
Book a free 45-minute consultation with a Red Planet Labs engineer to discuss your use cases, ask questions, or even pair program on using Rama to solve your problem. Since Rama is so concise, in some cases we've completed an application in a single pairing session!
TRY RAMA RIGHT NOW ON YOUR LOCAL MACHINE
Rama is available via a Maven dependency for experimentation in a simulated in-process environment. Clone the rama-demo-gallery repository to play with short, self-contained, thoroughly commented examples of applying Rama to a variety of use cases. Just run mvn test or lein test to run the examples. Read the tutorial to start learning Rama.
USE RAMA IN PRODUCTION FOR FREE
Rama is free to use up to two nodes. See the pricing page on the full details of what's included, and download at this link.
PURCHASE A LICENSE
A license lets you run larger clusters and use enterprise features. See the pricing page for details.
