PStates
Partitioned states ("PStates") index data to support all the various queries needed by applications. They are stored durably on disk and replicated. Much of Rama programming revolves around deciding how many PStates to create, how they will be structured, and how they will be updated. By being based on composable distributed data structures, PStates offer a tremendous amount of flexibility in how data is indexed as compared to traditional databases, and they’re a key reason why Rama is such a general platform able to build complex applications in a small amount of code on just a single tool.
PStates also provide a powerful new capability called "fine-grained reactive queries" that has never existed before. This feature enables applications to be reactive up and down the stack. Fine-grained reactive queries are fully incremental and revolve around the concept of a "diff" between versions of a value.
On this page you will learn:
-
The difference between Rama’s "flexible indexing model" versus the "fixed indexing model" of traditional databases
-
Declaring PStates and defining schemas
-
Using subindexing to efficiently store huge nested data structures
-
Querying and updating PStates in topologies
-
Using PState clients
-
Fine-grained reactive queries
All examples on this page can be found in the rama-examples project.
PStates versus databases
Databases vary a great deal in functionality offered. Each database provides a "data model", such as key/value, document, column-family based, relational, etc, and their APIs are oriented around what’s possible with each specific data model. If you’re using a database whose data model is unable to support a new use case, you’ll need to introduce another database into your architecture.
A more flexible way to think about indexing is in terms of data structures. A "data model" is really just a specific combination of data structures:
-
Key/value: Map
-
Document: Map of maps
-
Column-family based: Map of large sorted maps
-
Relational: Map of maps, with secondary indexes being additional maps
Some databases, such as Redis, offer a bit more flexibility. Redis allows values to be a variety of in-memory data structures, such as lists and sets. But you’re ultimately restricted to those particular combinations along with everything needing to fit into memory.
These data models are "fixed indexing models" – you have to make do with these particular combinations of data structures and try to fit your application’s use cases to them.
Rama takes a drastically different approach by exposing a "flexible indexing model", where every PState you create can be whatever combination of data structures you need. You can easily make as many PStates as needed to satisfy all your use cases. The particular data structure combination needed by any particular use case can be highly specific, so this flexibility is essential for being able to support all the varied needs of an application.
The data structure orientation of PStates also brings backend programming back in line with regular, everyday programming. One of the pillars of programming is choosing which data structures to use to represent your program data, whether maps, lists, sets, or others. Rama brings that basic concept back into the world of backend development.
Another huge difference between PStates and databases is how they’re updated. A database functions as global mutable state that can be written from anywhere, whereas a PState can only be updated by the ETL topology that owns it. While at first glance this seems like a restriction, it’s actually a major simplification of backend architecture that doesn’t constrain you at all.
Any write you could do to a database you can easily model in Rama as a depot append being consumed by an ETL topology to update a PState. Doing it this way offers some major benefits:
-
The depot represents an immutable log of all events that happened in your application. You can use this for analytics later, or as a source to recompute PStates were you to need to index information differently or fix corruption caused by a bug in your ETL code.
-
All writes to PStates being centralized in one ETL topology makes it much easier to grasp how data flows through your system.
-
Stream and microbatch topologies have very different operational characteristics, and centralizing all PState writes into one topology allows Rama to significantly optimize how those writes are implemented.
-
ETL topologies are inherently scalable and use the exact same scaling mechanism as used to scale PStates and depots.
If you want to change how an ETL topology updates PStates or add new functionality, you simply update the module.
Additionally, the integration of PStates, depots, and topologies onto the same set of processes/threads means there’s very little cost to the additional step of new data going to a depot first.
Finally, another major difference between PStates and databases is how reactivity is provided. Reactivity refers to being pushed notifications immediately when state you care about within an index changes. Databases provide, at best, "coarse-grained reactivity". These are typically called "triggers" and only tell you that a whole value has changed. They don’t tell you how that value has changed in any more detail. In Postgres or MySQL, for example, they only tell you that a particular row/column changed.
PStates, on the other hand, provide "fine-grained reactivity". No matter how nested a value is in a PState, with the proxy operation you receive fine-grained information about how that value changed in the form of "diffs". Diffs contain information like "The values at the keys 'k' and 'k2' in the subscribed map were updated" or "The value 'apple' was added to a set at the key 'fruit' on the map at index 3 on the subscribed list". Reactive queries are discussed in depth later on this page.
Declaring PStates
PStates are declared as part of a stream or microbatch topology. The API is the same in both cases. Here’s an example of declaring a few PStates for a stream topology:
public class BasicPStateDeclarationsModule implements RamaModule {
@Override
public void define(Setup setup, Topologies topologies) {
StreamTopology s = topologies.stream("s");
s.pstate("$$p1", Long.class);
s.pstate("$$p2", PState.mapSchema(String.class, Integer.class));
s.pstate(
"$$p3",
PState.mapSchema(
String.class,
PState.fixedKeysSchema(
"count", Integer.class,
"someList", PState.listSchema(String.class),
"someSet", PState.setSchema(Integer.class))));
}
}Every PState declaration requires a var beginning with "$$" and a schema. The schema specifies the combination of data structures for the PState. PStates are distributed objects that will have one partition on every task of its module (unless you declare it as global, described below). So "$$p1" in the example will have a single Long in each partition of the PState, and the other two PStates will have a map in each partition.
Schemas can be combined and nested any which way you need. At the leaves of schema declarations will always be references to Java classes. These examples show all the different kinds of schemas available:
-
mapSchema: Declares a map with a key class and a schema or class for the value. -
setSchema: Declares a set with the specified type as values. Values ofsetSchemacannot be other schemas. -
listSchema: Declares a list with the specified type or schema as values. -
fixedKeysSchema: Declares a map with a fixed set of keys, where each key has a separate schema for its value.
The top-level schema of a PState can only be a mapSchema, fixedKeysSchema, or class reference (we have it on our roadmap to change this so all schemas are usable at the top-level). You can still store lists and sets at the top-level, but that would be by using something like an ArrayList or a HashSet at the top-level. In this case, Rama won’t index the elements of the collection separately like it does for top-level mapSchema or fixedKeysSchema (more on this in the next section).
Subindexing
There are two ways in which schemas are implemented by Rama from an indexing perspective. Either the entire value is indexed, or each element of the collection is indexed separately. Top-level mapSchema or fixedKeysSchema index elements separately, and marking a nested schema as "subindexed" will cause that nested data structure to index its elements separately. All other schemas / class references index as single values.
PState schemas specify subindexing like so:
s.pstate(
"$$p",
PState.mapSchema(
String.class,
PState.setSchema(Long.class).subindexed()));
s.pstate(
"$$p2",
PState.mapSchema(
Integer.class,
PState.mapSchema(
String.class,
String.class).subindexed()));
s.pstate(
"$$p3",
PState.mapSchema(
String.class,
PState.mapSchema(
String.class,
PState.listSchema(Integer.class).subindexed())));"$$p" contains a subindexed set inside of a map, "$$p2" contains a subindexed map inside of a map, and "$$p3" contains a subindexed list inside a non-subindexed map inside of a map. You can also have subindexed structures inside other subindexed structures – this functionality composes infinitely.
The granularity of indexing determines how much work is done for reads and writes. If a structure is not subindexed, the entire structure needs to be read from disk even if you’re just querying for one element of it. For example, consider this query on "$$p3":
p3.selectOne(Path.key("a").key("b").nth(1))Suppose the contents of "$$p3" on that partition are:
{"a": {"b": <subindexed [10, 11, 12]>,
"c": <subindexed [3]>,
"d": <subindexed [4, 5]>,
"e": <subindexed [6, 7]>},
"x": {"f": <subindexed [8]>},
"y": {"g": <subindexed [9]>,
"h": <subindexed [10, 11]>}}The query navigates into the partition, step by step. The first step key("a") operates on the top-level map which indexes its elements separately, so it will read the value for "a". Because that submap in the schema is not sub-indexed, that value stores the entire contents of the map. So key("a") will read from disk:
{"b": <subindexed [10, 11, 12]>,
"c": <subindexed [3]>,
"d": <subindexed [4, 5]>,
"e": <subindexed [6, 7]>}If the data structure being resolved only has a small number of elements, like less than 50, the performance difference from being subindexed or not will be insignificant. But if it has a large number of elements, like 10 million, there will be a massive performance difference.
The next step key("b") reads the value for "b". Because that list is subindexed, it actually only reads from the already fetched map a unique identifier for the subindexed structure called the "reference ID". So instead of reading from disk the entire list, which could contains millions of elements, it only reads a small 8 byte value per subindexed structure. The data structure at that point of navigation acts just like a normal list, but to resolve list queries it uses its internal reference ID to find the individual elements on disk.
The next step nth(1) does a lookup on that subindexed list, which reads the value 11 from disk. The values 10 and 12 as well as all the other values in the other subindexed lists are never read from disk in this query.
Subindexed maps and sets are sorted. You can do efficient range queries on them using the navigators sortedMapRange, sortedMapRangeFrom, sortedMapRangeTo, sortedSetRange, sortedSetRangeFrom, and sortedSetRangeTo. These navigators are extremely smart about how they iterate on data on disk to resolve the substructure, generally doing just a single disk seek and a scan to resolve the entire substructure. For an example of usage, see this section from the Paths page.
Size tracking
Subindexed structures also provide special functionality for getting their sizes efficiently. By default, "size tracking" is turned on and fetching the size of a subindexed structure is an extremely fast operation running in O(1) time. Here’s an example of getting the size of a subindexed set from "$$p1" in the above example:
p1.selectOne(Path.key("a").view(Ops.SIZE))You can use Ops.SIZE to get the set’s size just like you could use the same operation on any regular Java data structure like an ArrayList or HashSet.
Size tracking requires Rama to perform additional work behind the scenes when doing writes to a subindexed structure, such as performing a read to see if the key or set value already exists. So it can be turned off when declaring the PState schema to improve write performance. Here’s an example of a PState with a subindexed set with size tracking turned off:
s.pstate(
"$$p",
PState.mapSchema(
String.class,
PState.setSchema(Long.class).subindexed(SubindexOptions.withoutSizeTracking())));This PState will perform writes to subindexed sets slightly faster, but getting the size of a subindexed set will be an O(n) operation. So if a subindexed set has millions of elements, getting the size will be extremely slow. We generally recommend keeping size tracking on unless the PState is in an extremely hot path and size tracking is absolutely not needed on those subindexed structures.
Deleting subindexed structures
You can remove subindexed structures just like how you would remove any other value. For example, in the PState $$p defined above, you could remove a nested subindexed set with a call like .localTransform("$$p", Path.key("a").termVoid()). Internally, Rama will remove the subindexed structure by doing an efficient range delete.
However, this only works if you directly delete the subindexed structure. If you instead remove a parent of the subindexed structure, the reference to the subindexed structure will be deleted but the individual elements on disk will not. For example, suppose your PState schema is this:
s.pstate("$$p",
PState.mapSchema(
Object.class,
PState.mapSchema(
Object.class,
PState.setSchema(Object.class).subindexed())));Now suppose you performed a delete like this:
.localTransform("$$p", Path.key("a").termVoid())The elements of any subindexed structures reachable from the top-level key "a" will not be deleted from disk. Instead, you should delete them explicitly before deleting the top-level key.
PState options
PStates have a few options available when declaring them. PStates use the builder pattern so you can easily string multiple options together.
The global option causes the PState to have a single partition on task 0 rather than a partition on every task. It’s used like so:
s.pstate("$$p", Object.class).global();An example use case for a global PState would be storing the "top 10" of some entity being tracked. It’s also commonly used for things like global counts and sums.
The option initialValue specifies the value to initialize each PState partition to when the module is first launched. It’s used like so:
s.pstate("$$p", Integer.class).initialValue(0);initialValue can only be used if the PState schema is a class reference. It’s commonly used with global, but there’s also many use cases for non-global PStates that aren’t top-level maps. One example is the PState used for ID generation in ModuleUniqueIdPState from rama-helpers.
The option makePrivate makes the PState inaccessible for reads for anything other than the owning topology. Here’s an example of usage:
s.pstate("$$p", Integer.class).global().makePrivate();Trying to access a private PState via RamaClusterManager or from another module will result in an exception.
Finally, the last PState option available is keyPartitioner. This changes how PState clients determine to which PState partition to send a query. For example, consider the following PState client query:
pstate.select(Path.key("a").all());The query extracts the key "a" from the query path and uses the configured key partitioner to route the query to the right partition. The default key partitioner is hash-based, and you can use the keyPartitioner option to implement things like sorted partitioning schemes.
The key partitioner is a function taking in as arguments the number of partitions for the PState and the extracted key. It returns the partition number to send the query. Here’s an example of configuring a key partitioner that routes every request to the last partition:
public class CustomKeyPartitionerModule implements RamaModule {
public static class LastPartitionFunction implements RamaFunction2<Integer, Object, Integer> {
@Override
public Integer invoke(Integer numPartitions, Object key) {
return numPartitions - 1;
}
}
@Override
public void define(Setup setup, Topologies topologies) {
StreamTopology s = topologies.stream("s");
s.pstate("$$p", Object.class).keyPartitioner(LastPartitionFunction.class);
}
}The configured key partitioner is also used when calling select in topologies, described more in the next section.
Using PStates in topologies
PStates are used in stream and microbatch topologies through Rama’s dataflow API methods localSelect, select, localTransform, agg, and compoundAgg. The first three methods use paths to target values to query and update within PStates.
Basic querying
localSelect queries the PState partition located on the current task. It emits one time for every navigated value. For example:
StreamTopology s = topologies.stream("s");
s.source("*depot").out("*k")
.localSelect("$$p", Path.key("*k").all()).out("*v")
.each(Ops.PRINTLN, "Emitted:", "*v");This topology code queries for every element inside a nested collection within "$$p". If the collection for a key has zero elements or doesn’t exist, the localSelect call won’t emit at all. If it has ten elements, localSelect will emit ten times.
localSelect is a synchronous call. Nothing else can happen on a task while a localSelect is running, meaning no other PStates on that task can change. You can string together multiple localSelect calls to look at values from multiple PStates synchronized to a moment in time.
select works just like localSelect except partitions the computation first based on the query path. For example:
StreamTopology s = topologies.stream("s");
s.source("*depot").out("*k")
.select("$$p", Path.key("*k").all()).out("*v")
.each(Ops.PRINTLN, "Emitted:", "*v");The path given to select must start with key, and the key provided will be used with the configured key partitioner on the PState to choose the target task. The key partitioner defaults to a hash-based partitioner and is equivalent to using hashPartition. Also, select always emits on the task it partitions to and not on the task it started from (unless those happen to be the same).
Yielding select
localSelect and select callsites accept an option "allow yield" which is useful for queries that need to operate over a large amount of data from the PState. For example, you may want to emit every element of a subindexed set that could have hundreds of thousands of entries in it. The "allow yield" option allows queries like this to be done without holding the task thread for an extended amount of time. See this section for a discussion of why it’s important to not hold the task thread for more than a few milliseconds at a time.
When the "allow yield" option is specified, the localSelect or select call will execute over the course of many individual events – potentially thousands of them. Here is an example of specifying the option:
.localSelect("$$p", Path.key("cagney").all(), SelectOptions.allowYield()).out("*v")The results of the query are identical to as if that option were not specified. The only change is how it executes. Even though the query executes over many events, it operates over a stable view of the PState. So any transforms that happen to the PState after the query begins will not be seen by the query.
It’s important to note that when that option is set, subsequent code may not be synchronous with the start of the query. When allowYield is specified, multiple PStates cannot be guaranteed to be read from at the same point in time like you can when that option is not specified.
Yielding selects automatically break up large chunks of work with pagination, such as when navigating to every element of a subindexed structure with .all(). The default page size is specified with the dynamic option pstate.yielding.select.page.size, and it can be adjusted mid-path with the .withPageSize navigator. For example:
.localSelect("$$p", Path.key("cagney").all().withPageSize(100, Path.all().mapVals()).mapKeys(), SelectOptions.allowYield()).out("*v")If the default page size is set to 250, the first .all() and the .mapKeys() will use a page size of 250, while the second .all() and the .mapVals() will use a page size of 100. Different page sizes may be more optimal for data of different sizes, with experimentation needed to determine the best setting for any particular use case. Rama’s default performs well for most use cases.
Transforming
PStates are updated by using localTransform, agg, or compoundAgg. As mentioned earlier, they can only be written to by their owning topology. Stream and microbatch topologies implement PState writes very differently in order to achieve high performance.
localTransform uses transform paths to specify updates. Just like queries, transform paths use navigation to target subvalues within a PState. See the documentation on the Paths page for details.
A higher level mechanism for updating PStates is by using aggregators through agg or compoundAgg. See the Aggregators page for details.
Querying from other modules
Lastly, querying PStates from other modules is almost exactly the same. You can use localSelect and select in the same way, with only a minor difference in how you tell Rama which partition of the target PState to interact with. Since queries on mirror PStates execute asynchronously anyway, they always use yielding selects. Specifying the .allowYield() option manually is thereby not allowed.
See the Module dependencies page for details.
Using PState clients
A PState client is retrieved from RamaClusterManager on a real cluster, or from InProcessCluster in a test environment. Connecting to a Rama cluster to fetch PState clients is discussed more on this page.
A PState client performs point queries. It fetches information from one partition of one PState. This is in contrast to query topologies which can do much more sophisticated queries spanning many PStates and many partitions. But whereas query topologies are defined as part of a module, PState client queries can be specified in ad-hoc ways. The Path API for specifying point queries is extremely powerful and flexible. PState clients use yielding selects, so there’s no restriction on how large the queries can be.
This section will cover the non-reactive query API on PState clients, and the next section will cover reactive queries. The non-reactive API consists of a few variations of select and selectOne. select returns a list of navigated results, while selectOne returns one value and requires the provided Path navigates to exactly one value. Here’s an example of using both these methods:
public class ClientBasicSelectExamplesModule implements RamaModule {
@Override
public void define(Setup setup, Topologies topologies) {
setup.declareDepot("*depot", Depot.hashBy(Ops.FIRST));
StreamTopology s = topologies.stream("s");
s.pstate("$$p",
PState.mapSchema(
String.class,
PState.setSchema(Long.class)));
s.source("*depot").out("*tuple")
.each(Ops.EXPAND, "*tuple").out("*k", "*v")
.compoundAgg("$$p", CompoundAgg.map("*k", Agg.set("*v")));
}
public static void main(String[] args) throws Exception {
try(InProcessCluster cluster = InProcessCluster.create()) {
RamaModule module = new ClientBasicSelectExamplesModule();
cluster.launchModule(module, new LaunchConfig(4, 4));
String moduleName = module.getClass().getName();
Depot depot = cluster.clusterDepot(moduleName, "*depot");
PState p = cluster.clusterPState(moduleName, "$$p");
depot.append(Arrays.asList("cagney", 1));
depot.append(Arrays.asList("cagney", 7));
depot.append(Arrays.asList("cagney", 3));
depot.append(Arrays.asList("cagney", 8));
depot.append(Arrays.asList("davis", 10));
depot.append(Arrays.asList("davis", 12));
depot.append(Arrays.asList("davis", 14));
System.out.println(
"select (davis): " + p.select(Path.key("davis")));
System.out.println("selectOne (davis): " + p.selectOne(Path.key("davis")));
System.out.println(
"select (cagney): " +
p.select(Path.key("cagney").all().filterPred(Ops.IS_ODD)));
}
}
}This module produces a simple PStating mapping keys to sets. The main method launches the module in an InProcessCluster, adds some test data, and performs some queries using select and selectOne. Running this prints:
select (davis): [#{12 14 10}]
selectOne (davis): #{12 14 10}
select (cagney): [7 1 3]The first two queries are comparisons of the returns of select and selectOne for the same path. select returns a list of navigated values, and selectOne returns the sole navigated value. That’s why the first select returns a list with one element (the #{…} syntax indicates a set) and the selectOne call returns just the set.
The last select uses all to navigate to all the odd elements in the set for "cagney". The result is a list of all navigated values.
Note that select on a PState client returns results differently than localSelect or select within a topology. The topology methods emit once for each navigated value, while select on a PState client returns all navigated values as a list.
This example barely scratches the surface on what you can express with paths. Paths can descend into subvalues, navigate to substructures, do range queries, aggregate subvalues, and more. Be sure to read the Paths page to explore their potential.
Function objects are commonly used within paths for filtering and views. For instance, the above example uses Ops.IS_ODD. For a function object, or any object for that matter, to be usable within a path the class of that object must be on the classpath of both the client and the module. Lambdas are not usable in PState client paths for this reason. It’s reasonable to include function implementations within a module deploy solely for use by PState clients, as this would be part of the functionality exposed to users of the module.
How client queries are routed
When using select or selectOne, the PState client must decide to which PState partition to send the query request. If the PState has only one partition, by being declared global or the module having only one task, then the query is always sent to that partition and there are no restrictions on the path used for the query.
When the PState has more than one partition, the select and selectOne variants that only take in a path as input (like shown in the previous section) use the path to determine which PState partition to query. They require the path begin with the key navigator, and the key from that navigator is extracted and used to choose the PState partition. This key is given to the "key partitioner" configured during the PState declaration to make that choice. The key partitioner defaults to a hash-based partitioner if not configured, which is equivalent to using hashPartition in a topology.
There’s another variant of select and selectOne which take in the partitioning key as an additional argument. This variant uses this explicit partitioning key along with the configured key partitioner to route the query, and there are no restrictions on the path used for the query.
An example of where an explicit partitioning key is useful comes from our Twitter-scale Mastodon implementation. Mastodon identifies "statuses" (Mastodon’s name for tweets) by a combination of "user ID" and "status ID". The "Core" module in Mastodon handles both user profiles and status indexing. Three of the PStates in "Core" are:
-
"$$accountIdToAccount": a map from user ID to profile information -
"$$accountIdToStatuses": a map from user ID to a subindexed map of status ID to status content versions -
"$$statusIdToFavoriters": aKeyToLinkedEntitySetPStateGroup(from rama-helpers), which is a map from status ID to a linked set of user IDs who have liked that status
All these PStates are kept colocated by the user ID of a status. Colocating them greatly improves the efficiency of rendering timelines for users, which involves fetching all associated profile information and status stats (like count, boost count, etc.) for a collection of statuses. However, the "$$statusIdToFavoriters" PState doesn’t include the user ID as part of its PState structure because it’s unnecessary and inefficient. Status IDs are already unique within the module. So the "$$statusIdToFavoriters" PState is partitioned by a value (the user ID) that isn’t part of the data within it.
The explicit partitioning key variants of select and selectOne allow the "$$statusIdToFavoriters" PState to be queried by a PState client like so:
statusIdToFavoriters.selectOne(userId, Path.key(statusId).view(Ops.SIZE));This queries the number of likes for a particular status. The user ID is used as the partitioning key, and the status ID is used to navigate the PState partition. More generally, the explicit partitioning key variants of select and selectOne are useful whenever a PState is partitioned by something other than top-level keys in its structure.
Non-blocking API
The select and selectOne variants shown so far will block the thread while waiting for a response from the cluster. There are also non-blocking variants of these that return CompletableFuture objects.
Here are a few examples of using the non-blocking API:
CompletableFuture f = p.selectAsync(Path.key("cagney").all().filterPred(Ops.IS_ODD));
CompletableFuture f2 = p.selectOneAsync(Path.key("davis"));
CompletableFuture f3 = likes.selectOneAsync("cagney", Path.key(123).view(Ops.SIZE));CompletableFuture has a rich API for composing with other CompletableFuture objects and for registering callbacks for notification of success or failure.
Reactive queries
The reactive query operations on a PState client are called proxy. They work exactly like selectOne, except instead of returning a static value they return a stateful object called ProxyState whose value updates in the background as the corresponding value on the cluster changes. Like selectOne, there is also a variant accepting an explicit partitioning key, and there are non-blocking variants called proxyAsync.
The path used for a proxy call must navigate to exactly one value, but otherwise has no restrictions. You can proxy a literal subvalue, or you can proxy a substructure or view. The full flexibility of paths is at your disposal when forming reactive queries.
There’s a huge difference between the level of reactivity provided by proxy versus reactive features like triggers provided by databases. The reactivity provided by proxy is fine-grained. When the state on a PState changes, instead of sending the full new value back to a subscribed ProxyState, it instead sends back the minimal "diff" encapsulating the change. This diff is incrementally applied to the ProxyState, and you can inspect and react to these diffs as well.
Let’s take a look at an example to understand this more concretely:
public class BasicReactiveModule implements RamaModule {
@Override
public void define(Setup setup, Topologies topologies) {
setup.declareDepot("*depot", Depot.hashBy(Ops.FIRST));
StreamTopology s = topologies.stream("s");
s.pstate("$$p", PState.mapSchema(String.class, PState.mapSchema(String.class, Long.class)));
s.source("*depot").out("*tuple")
.each(Ops.EXPAND, "*tuple").out("*k1", "*k2")
.compoundAgg("$$p", CompoundAgg.map("*k1", CompoundAgg.map("*k2", Agg.count())));
}
public static void main(String[] args) throws Exception {
try(InProcessCluster cluster = InProcessCluster.create()) {
RamaModule module = new BasicReactiveModule();
cluster.launchModule(module, new LaunchConfig(4, 4));
String moduleName = module.getClass().getName();
Depot depot = cluster.clusterDepot(moduleName, "*depot");
PState p = cluster.clusterPState(moduleName, "$$p");
depot.append(Arrays.asList("a", "b"));
depot.append(Arrays.asList("a", "c"));
ProxyState<Map> proxy = p.proxy(Path.key("a"));
System.out.println("Initial value: " + proxy.get());
depot.append(Arrays.asList("a", "d"));
Thread.sleep(50);
System.out.println("New value: " + proxy.get());
depot.append(Arrays.asList("a", "c"));
Thread.sleep(50);
System.out.println("New value: " + proxy.get());
}
}
}The main method launches a simple module which maintains a PState containing a map of maps. It then uses proxy to get a ProxyState for the key "a". This object has one method get to retrieve the current value for that path. get does not re-query the path – the ProxyState is pushed incremental changes from the server.
Running main prints:
Initial value: {"b" 1, "c" 1}
New value: {"b" 1, "c" 1, "d" 1}
New value: {"b" 1, "c" 2, "d" 1}When the proxy initially resolves, the value inside the ProxyState is {"b" 1, "c" 1}. Then the depot is appended ["a", "d"] which adds a new entry to the map inside the ProxyState. The server does not send the full new map back ({"b" 1, "c" 1, "d" 1}). Instead it sends an object called KeyDiff which says "the key 'd' was added with the value 1". This diff is then applied to the current value of the ProxyState to reconstruct the corresponding value on the PState. This is far more efficient than sending the full map back, especially if the map has a large number of entries.
The callbacks for subscribers of a PState partition are triggered as soon as the data changes on the server. Since that is asynchronous to receiving the ack for the depot append, this code inserts a short sleep to give time for that asynchronous callback to be received and processed by the ProxyState.
Let’s look at this example again but with a callback registered with the proxy call so you can see the diffs being sent back:
public class CallbackReactiveModule implements RamaModule {
@Override
public void define(Setup setup, Topologies topologies) {
setup.declareDepot("*depot", Depot.hashBy(Ops.FIRST));
StreamTopology s = topologies.stream("s");
s.pstate("$$p", PState.mapSchema(String.class, PState.mapSchema(String.class, Long.class)));
s.source("*depot").out("*tuple")
.each(Ops.EXPAND, "*tuple").out("*k1", "*k2")
.compoundAgg("$$p", CompoundAgg.map("*k1", CompoundAgg.map("*k2", Agg.count())));
}
public static void main(String[] args) throws Exception {
try(InProcessCluster cluster = InProcessCluster.create()) {
RamaModule module = new CallbackReactiveModule();
cluster.launchModule(module, new LaunchConfig(4, 4));
String moduleName = module.getClass().getName();
Depot depot = cluster.clusterDepot(moduleName, "*depot");
PState p = cluster.clusterPState(moduleName, "$$p");
depot.append(Arrays.asList("a", "b"));
depot.append(Arrays.asList("a", "c"));
ProxyState<Map> proxy = p.proxy(Path.key("a"), new ProxyState.Callback<Map>() {
@Override
public void change(Map newVal, Diff diff, Map oldVal) {
System.out.println("Received callback: " + newVal + ", " + diff + ", " + oldVal);
}
});
depot.append(Arrays.asList("a", "d"));
depot.append(Arrays.asList("a", "c"));
Thread.sleep(50);
}
}
}This example runs the exact same module with the same ProxyState and the same depot appends. It additionally adds a callback onto the proxy call which is invoked immediately after a diff is received and applied to the value in the ProxyState. The callback receives as input the new value of the ProxyState, the diff data, and the value of the ProxyState before the diff was applied.
Running this prints:
Received callback: {"b" 1, "c" 1}, ResyncDiff[], null
Received callback: {"b" 1, "c" 1, "d" 1}, KeyDiff[d | NewValueDiff[1]], {"b" 1, "c" 1}
Received callback: {"b" 1, "c" 2, "d" 1}, KeyDiff[c | NewValueDiff[2]], {"b" 1, "c" 1, "d" 1}The first callback received is the initial value for the ProxyState. The ResyncDiff object indicates the value was recomputed from scratch by executing the path like a selectOne call.
The subsequent callbacks show the incremental data pushed from the PState to this ProxyState. The depot append of ["a", "d"] pushes KeyDiff[d | NewValueDiff[1]] back. KeyDiff contains two fields: the affected key, and the diff for the value of that key. The NewValueDiff here says the value for "d" changed to 1. In the callback you can see the difference between the old value and new value is exactly this diff. You can also see each subsequent callback receives the new value from the previous callback as its old value, as expected.
Every callback for a proxy call runs in the background on a dedicated thread from a thread pool. This guarantees diffs are processed in exactly the order in which they were sent back from the PState.
Diffs
The diff types in Rama represent all the different ways a map, list, set, or multi-set can change. A map can have keys updated, values updated, or entries removed. A list can have elements appended, inserted, updated, reordered, or removed. Sets and multi-sets can have elements added or removed.
All these diffs are broadly categorized as top-level diffs or low-level diffs. A top-level diff captures change as compactly as possible, while a low-level diff specifies change in terms of locations like keys or indexes. Many diffs can be converted into one or more other diffs during processing. For example, a SequenceInsertDiff represents a single element being inserted in between two indexes in a list and contains two fields: an index and a value. Since inserting an element in the middle of a list grows the list by one element and changes the value for every index after the insertion point (by shifting every value by one index), one SequenceInsertDiff can be converted into a collection of many KeyDiff and one AppendDiff.
Diffs sent as callbacks from a PState to a ProxyState are always top-level diffs. The full set of diffs available in Rama are shown in the diagram below, with arrows indicating how diffs convert to other diff types:
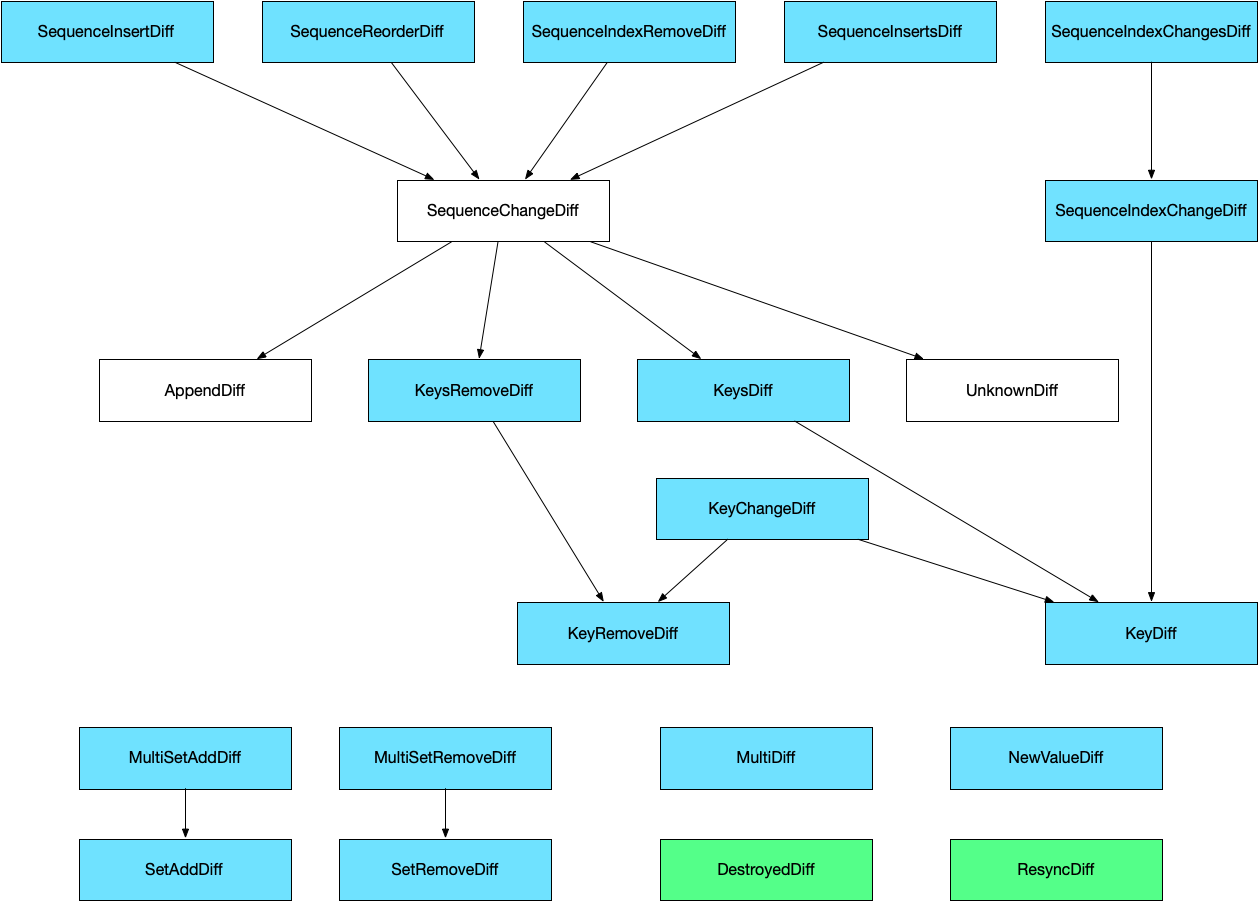
The diffs colored in blue are top-level diffs. The diffs colored in green can also be top-level diffs, but have special meaning:
-
ResyncDiff: Used the first time a proxy callback is invoked, or any time aProxyStateis resynced from scratch due to some sort of error (see Fault Handling below). -
DestroyedDiff: Used for the final callback aftercloseis called on aProxyState. -
UngracefulTerminationDiff: Used for the final callback when aProxyStateself-terminates due to having too many errors (almost always caused by a code issue with the path).
The Javadoc for each diff type explains what the diff means, what fields it has, and how it converts to other diffs. You’ll see in the next section how you can choose which diff types you wish to process and how Rama will automatically do any diff conversion necessary.
The diffs produced on a PState are determined entirely by the paths used in localTransform callsites or the aggregators used in agg or compoundAgg callsites. The diffs are computed incrementally as part of the transform, and they’re only computed if there are any subscribers on the PState. Not every transform affects every subscriber, and only a portion of a diff may be applicable to any particular subscriber. Let’s take a look at an example of this:
public class MultiSubscriberModule implements RamaModule {
@Override
public void define(Setup setup, Topologies topologies) {
setup.declareDepot("*depot", Depot.hashBy(Ops.IDENTITY));
StreamTopology s = topologies.stream("s");
s.pstate("$$p", Map.class).global();
s.source("*depot").out("*k")
.localTransform("$$p", Path.key("*k").nullToVal(0).term(Ops.INC));
}
public static void main(String[] args) throws Exception {
try(InProcessCluster cluster = InProcessCluster.create()) {
RamaModule module = new MultiSubscriberModule();
cluster.launchModule(module, new LaunchConfig(1, 1));
String moduleName = module.getClass().getName();
Depot depot = cluster.clusterDepot(moduleName, "*depot");
PState p = cluster.clusterPState(moduleName, "$$p");
depot.append("a");
depot.append("b");
depot.append("c");
ProxyState<Map> proxyTop = p.proxy(Path.stay(), new ProxyState.Callback<Map>() {
@Override
public void change(Map newVal, Diff diff, Map oldVal) {
System.out.println("'top' callback: " + newVal + ", " + diff + ", " + oldVal);
}
});
ProxyState<Integer> proxyA = p.proxy(Path.key("a"), new ProxyState.Callback<Integer>() {
@Override
public void change(Integer newVal, Diff diff, Integer oldVal) {
System.out.println("'a' callback: " + newVal + ", " + diff + ", " + oldVal);
}
});
ProxyState<Integer> proxyB = p.proxy(Path.key("b"), new ProxyState.Callback<Integer>() {
@Override
public void change(Integer newVal, Diff diff, Integer oldVal) {
System.out.println("'b' callback: " + newVal + ", " + diff + ", " + oldVal);
}
});
depot.append("a");
depot.append("a");
depot.append("c");
depot.append("b");
Thread.sleep(50);
}
}
}The module in this example produces a global PState with a map of counts. The main method creates proxies on the top-level of the PState and to the values for the "a" and "b" keys. Running main prints:
'top' callback: {"a" 1, "b" 1, "c" 1}, ResyncDiff[], null
'a' callback: 1, ResyncDiff[], null
'b' callback: 1, ResyncDiff[], null
'a' callback: 2, NewValueDiff[2], 1
'top' callback: {"a" 2, "b" 1, "c" 1}, KeyDiff[a | NewValueDiff[2]], {"a" 1, "b" 1, "c" 1}
'a' callback: 3, NewValueDiff[3], 2
'top' callback: {"a" 3, "b" 1, "c" 1}, KeyDiff[a | NewValueDiff[3]], {"a" 2, "b" 1, "c" 1}
'top' callback: {"a" 3, "b" 1, "c" 2}, KeyDiff[c | NewValueDiff[2]], {"a" 3, "b" 1, "c" 1}
'top' callback: {"a" 3, "b" 2, "c" 2}, KeyDiff[b | NewValueDiff[2]], {"a" 3, "b" 1, "c" 2}
'b' callback: 2, NewValueDiff[2], 1Here you can see the diffs produced at the top-level of the PState are always KeyDiff, but the proxies for "a" and "b" only receive the portion of that diff that affects their values. Underneath the hood, PStates separate subscriptions by key to efficiently skip them when the transform doesn’t affect them.
The top-level diffs are KeyDiff because that’s the diff produced by the key navigator in this case. If key were used in conjunction with termVoid, it would produce a KeyRemoveDiff instead. The Javadoc for each navigator lists the diffs they produce.
agg and compoundAgg callsites can also be used to update PStates. Underneath the hood these callsites compile to localTransform calls using paths. CompoundAgg.map compiles to key and CompoundAgg.list compiles to multiple calls to nth.
The specificity of produced diffs depends on the specificity of the corresponding transforms. If a transform precisely targets a subvalue, the diff will be very specific. However, if it does something coarse-grained like a termVal on an entire substructure just to change one value nested within, the diff will be coarse-grained and inefficient to process by subscribers. Fortunately, highly specific paths are easier and more natural to use anyway.
Another note about this example: the top-level schema is Map.class instead of PState.mapSchema(String.class, Integer.class) because you cannot proxy objects which index their elements separately (top-level map or subindexed schemas). You can proxy values within them, just not the object itself.
Processing diffs
Capturing diffs in proxy callbacks and analyzing them is the basis for powering higher level reactivity in an application. For example, your diff processing could trigger fine-grained changes to your frontend UI.
Diffs contain a double dispatch based API for processing. This API makes it easy to specify which diffs you want to process while having Rama automatically convert any diffs for you. Let’s take a look at an example:
public static class MyProcessor implements Diff.Processor, KeyDiff.Processor {
public List processedKeys = new ArrayList();
@Override
public void processKeyDiff(KeyDiff diff) {
processedKeys.add(diff.getKey());
}
@Override
public void unhandled() {
processedKeys = null;
}
}
public static void processKeysDiff() {
Map m = new HashMap(2);
m.put("a", new NewValueDiff(1));
m.put("x", new NewValueDiff(2));
m.put("d", new NewValueDiff(3));
m.put("y", new NewValueDiff(4));
Diff diff = new KeysDiff(m);
MyProcessor processor = new MyProcessor();
diff.process(processor);
System.out.println("Processed keys 1: " + processor.processedKeys);
MyProcessor processor2 = new MyProcessor();
new UnknownDiff().process(processor2);
System.out.println("Processed keys 2: " + processor2.processedKeys);
}Diffs are processed by calling process on them with an object implementing the processing logic. Every diff type defines an inner interface Processor with a method specific to that diff. KeyDiff.Processor defines processKeyDiff, AppendDiff.Processor defines processAppendDiff, and so on. To specify the diff types in the hierarchy you wish to handle, your processor just implements the Processor interfaces for those diff types. In addition, the processor object must implement Diff.Processor which defines the method unhandled.
After calling process, Rama will expand that diff until every expanded diff can be handled by the provided processor. If that’s impossible, no processing is done and unhandled is called instead.
Running this prints:
Processed keys 1: [x, a, y, d]
Processed keys 2: nullIn the first case, you can see the processor only implements KeyDiff.Processor but was able to process a KeysDiff. If you consult the diagram earlier on this page, you’ll see this is because KeysDiff expands to many KeyDiff. In the second case, the provided processor cannot handle UnknownDiff so the unhandled method is called and the result is set to null.
process will process diffs in the order in which they happened. This can be significant for a case like a SequenceInsertDiff and a SequenceChangeDiff, where the order in which those happened can completely change the result. For the above example, each key in a KeysDiff is independent so the order in which each key’s diff happened doesn’t affect the result. So KeysDiff is expanded in an arbitrary order.
Although the diffs produced for a proxy are entirely predictable from the paths used in the PState transforms, it’s critical to still handle the case where unhandled is called on your processor. During normal operation, the diffs sent back to a ProxyState will be the fine-grained diffs expected from the transform paths. However, if something goes wrong – like a network error or overloaded cluster – a ProxyState can be forced to resync from scratch. In these cases it will re-execute the path and produce a ResyncDiff. Your processing code in this case should analyze the new value in its entirety and perhaps do a comparison against the old value. If you are using reactivity to render a UI, this could involve re-rendering an entire component from scratch.
As long as your cluster is appropriately provisioned, these recompute scenarios should be extremely rare. The vast majority of the time you should expect your reactivity code to receive fine-grained diffs. But for an application to be completely robust, it’s important to handle these rare failure scenarios as well.
Fault handling
proxy has an extremely robust implementation, carefully designed to ensure the value inside ProxyState matches the value that would be produced from freshly executing the path used to create the ProxyState.
Internally, diffs are sent back to a ProxyState along with a CRC. The CRC is checked after applying the diff, and if it doesn’t match the ProxyState will resync from scratch. This ensures integrity of the ProxyState in the face of any of the numerous failures that could happen in a distributed system.
A ProxyState also heartbeats to its subscribed PState partition on a fixed interval. This continuously validates it’s still subscribed on the PState partition, and it also lets the server know the ProxyState is still active so as not to cleanup the subscription. If the heartbeat finds the subscription is not there, the ProxyState will resync from scratch.
ProxyState cleanup and garbage collection
An active ProxyState uses resources on the process of the subscribed PState partition. The PState partition uses memory to track the subscription and uses CPU to process diffs for the subscription. The PState client for an active ProxyState also uses resources to regularly heartbeat and process incoming diffs.
All state for a ProxyState on both the client and server can be cleaned up by calling close on it. It’s best to call close as soon as a ProxyState is no longer needed in order to clean up resources as promptly as possible. Calling close also sends a final DestroyedDiff to the callback for the associated proxy call.
A PState partition will still clean up stale subscriptions that weren’t closed properly. If a PState partition hasn’t received a heartbeat from a ProxyState after a configurable timeout, it will clean up all resources used for the subscription and stop considering it for diff processing.
Handling of bad proxies
Rama provides protection against a bad proxy path (that causes an exception when being executed) repeatedly failing. By default, if a proxy errors 10 times within 120 seconds, it is forcibly terminated and an UngracefulTerminationDiff is sent to its callback if specified. This is true whether the error happened on the initial query for the proxy or the reactive processing to handle changes. The failure window size and threshold can be configured.
Schema validation
By default, a PState schema is fully enforced on every write. So if you try to write a list to a location that’s declared as a map schema, you’ll get an exception on write. Or if you try to write a string that’s declared as an integer, you’ll also get an exception.
There are two types of validation done by PStates that can be expensive, and both of these can be turned off. We recommend keeping these configurations on during development, and you should consider turning them off when deploying to production if you need better performance from the PStates in that module.
The first is validating that subindexed structures aren’t moved to another location. For example, suppose you had a PState declared with the schema:
PState.mapSchema(PState.setSchema(Object.class).subindexed())Then suppose you had an existing subindexed set at key "a". Code like this is invalid:
.localSelect("$$p", Path.key("a")).out("*s")
.localTransform("$$p", Path.key("b").termVal("*s")))The same subindexed structure cannot be stored in multiple locations, since that prevents Rama from being able to do optimized size tracking. So Rama by default disallows that with a runtime check that involves a disk read. You can disable this check by setting the config pstate.validate.subindexed.structure.locations in the config overrides for the module to false.
Another part of schema checking that can be expensive are large non-subindexed data structures. For examples, consider a schema like this:
PState.mapSchema(String.class,
PState.mapSchema(Long.class,
PState.mapSchema(String.class,
PState.setSchema(Long.class))))The values in the top-level map are stored as single values and contain doubly nested data structures. Every time one of those values is written, Rama iterates through the entire value to check that every key and value at every level of the data structure matches the schema. This can use a lot of CPU and significantly reduce the throughput of the ETL.
Fortunately, declaring large non-subindexed values like this is not common when developing Rama modules. If you do have a module with a PState like this, you can disable these checks by setting the config pstate.maximal.schema.validations to false. When that config is false, Rama will still do some schema validation, like checking the types of keys and values, but it won’t do that expensive iteration through non-subindexed values.
Migrations
A PState can be migrated to a new schema as part of a module update. A migration can include arbitrary user-specified transformation functions indicating how locations in the PState should change. PState migrations take effect immediately, with all subsequent reads after the module update returning migrated values. Rama accomplishes this by applying the migration function on read while it migrates the PState on disk in the background. The existence of a migration doesn’t slow down the module update at all.
The possible migrations include:
-
Changing the type and value of objects within a PState
-
Converting locations of a PState from non-subindexed to subindexed
-
Adding and removing keys from fixed keys schemas
A migration could do multiple of these at the same time, such as converting a non-subindexed set of numbers to a subindexed list of strings.
A migration is specified as part of a PState’s schema. For example, suppose your module currently has a PState declared like this:
s.pstate(
"$$p",
PState.mapSchema(
Long.class,
Long.class));You could migrate the values of that PState to strings ending with "!" like this:
s.pstate(
"$$p",
PState.mapSchema(
Long.class,
PState.migrated(
String.class,
"myMigrationId",
(Object o) -> {
if(o instanceof String) return o;
else return o.toString() + "!";
})));PState.migrated is the entire API for migrations. Its parameters are:
-
The new schema for the location, in this case
String.class -
The migration ID, which is used to determine if a migration should be restarted or continue where it left off if the module is updated mid-migration. If this remains the same, it continues where it left off. Otherwise, it restarts from the beginning of the PState. Here the migration ID is specified as
"myMigrationId". -
The migration function, which specifies how to change old values to the new schema. Here it’s a Java lambda with plain Java code to do the transformation. It could also be specified as a method reference, a built-in function from the Ops class, or as a RamaFunction1 class implementation.
As mentioned, as soon as the module update is done all reads will return fully migrated values. The migration does not delay the module update at all, and Rama will migrate the values on disk in the background. Since Rama doesn’t know precisely which parts of the PState have been migrated on disk, it applies the migration function on every read until the disk migration is complete. For this reason migration functions must be idempotent, which is why the function in this example starts off with if(o instanceof String).
PState.migrated has several options that can be specified on it for migrating a location to a subindexed structure or adding/removing keys from a fixed keys map. For example, suppose you had this PState:
s.pstate(
"$$p",
PState.mapSchema(
Integer.class,
Integer.class));You could migrate the value to a subindexed set like this:
s.pstate(
"$$p",
PState.mapSchema(
Integer.class,
PState.migrated(
PState.setSchema(String.class).subindexed(),
"anotherMigration",
(Object num) -> {
if(num instanceof Set) return num;
else {
Set ret = new HashSet();
for(int i=0; i<num; i++) {
ret.add("" + i);
}
return ret;
}
}
).migrateToSubindexed()));In this case the values pre-migration were numbers, and they become a subindexed set of strings from "0" until one minus the original number. Though Rama could infer from comparing the two schemas that the location is being changed to a subindexed structure, the migrateToSubindexed() option is required in order to make mistakes less likely.
Adding/removing keys from a fixed keys schema is similar. For example, suppose you start with this PState:
s.pstate(
"$$users",
PState.mapSchema(
String.class,
PState.fixedKeysSchema(
"age", Integer.class,
"location", String.class,
"occupation", String.class
)));You could do a migration that lowercases all values of "location", removes the "occupation" field, and adds a "score" field with a starting value of 10 like this:
s.pstate(
"$$users",
PState.mapSchema(
String.class,
PState.migrated(
PState.fixedKeysSchema(
"age", Integer.class,
"location", String.class,
"score", Integer.class
),
"fixedKeyExampleMigration",
(clojure.lang.IPersistentMap m) -> {
if(m.containsKey("score")) return m;
else {
return m.without("occupation")
.assoc("score", 10)
.assoc("location", ((String) m.get("location")).toLowerCase());
}
}).addFixedKeys("score")
.removeFixedKeys("occupation")
));Again, Rama could infer what keys are being added and removed, but it requires the options to be explicit to minimize the chance of a mistake. The migration function uses the existence of the "score" key to detect if the value has already been migrated, and otherwise performs the necessary transformations as plain Java code.
The specific type of the input map to that lambda function depends on how it was originally constructed, which is entirely under your control in your topology code. If the map was constructed by a path, such as Path.key("k1", "k2").termVal(10), the first time it runs on that location within the PState it will make an immutable map type implementing clojure.lang.IPersistentMap. That type of map uses structural sharing so that puts/removes are highly efficient while returning a new immutable instance. Most importantly, transforms with Rama paths (such as with .key) only work on these immutable data structures and won’t work on a mutable structure such as java.util.HashMap. So it’s important your migration function not change the types of data structures such that topology code which later writes to that location can’t function. That’s why the migration function in this example returns a new clojure.lang.IPersistentMap rather than converting it to something like a java.util.HashMap.
If your topology code explicitly made that location a different type, such as with the path Path.key("k1").term((o) → new HashMap()), then your migration code should make sure to maintain the HashMap type if topology code depends on it.
PState locations that can have migrations
As discussed above in the section on subindexing, a location in a PState is either indexed as a whole or has its elements indexed individually. The only parts of a PState that can have migrations declared with PState.migrated are full values. You can’t declare a migration on a location that’s indexed as part of a bigger value. The only locations that can have migrations are values of top-level maps or values of subindexed structures.
For example, here’s a valid migration:
s.pstate(
"$$users",
PState.mapSchema(
String.class,
PState.mapSchema(
Long.class,
PState.migrated(
String.class,
"myMigration",
(o) -> o.toString())
).subindexed()));Since the containing map is subindexed, the value of that map can be migrated. On the other hand, this is not a valid migration:
s.pstate(
"$$users",
PState.mapSchema(
String.class,
PState.mapSchema(
Long.class,
PState.migrated(
String.class,
"myMigration",
(o) -> o.toString())
)));Since the containing map is not subindexed, the targeted value is part of a greater value and a migration cannot be performed. That migration could instead be written like this by moving the migration up to the complete value:
s.pstate(
"$$users",
PState.mapSchema(
String.class,
PState.migrated(
PState.mapSchema(Long.class, String.class),
"myMigration",
(clojure.lang.IPersistentMap m) -> {
IPersistentMap ret = m;
for(Object k: m.keySet()) {
ret = ret.assoc(k, ret.get(k).toString());
}
return ret;
})));Likewise, since locations with a fixed keys schema are indexed as a single value, you cannot declare a migration on a value in a fixed keys schema. This is invalid:
s.pstate(
"$$users",
PState.mapSchema(
String.class,
PState.fixedKeysSchema(
"age",
Integer.class,
"location",
PState.migrated(
String.class,
"myMigration",
(o) -> o.toString()))));Instead, you’d have to declare the migration on the fixed keys schema as a whole.
Finally, keys of top-level or subindexed maps and values of subindexed sets cannot be migrated. So a migration like this is invalid:
s.pstate(
"$$users",
PState.mapSchema(
String.class,
PState.setSchema(
PState.migrated(
String.class,
"myMigration",
(o) -> o.toString())
).subindexed()));If you try to deploy an invalid migration to a Rama cluster, the deploy will be rejected.
If you need to do a migration that’s not supported by the migration API, the best approach is usually to recompute a new PState from depot data.
Nested migrations
There can be any number of migrations on the same PState, including nested within one another. Here’s an example:
s.pstate(
"$$movieReviews",
PState.mapSchema(
String.class,
PState.migrated(
PState.fixedKeysSchema(
"audience",
PState.mapSchema(String.class, String.class).subindexed(),
"critics",
PState.mapSchema(
String.class,
PState.migrated(
String.class,
"nestedMigrationId",
(String s) -> s.toLowerCase())
).subindexed())
"topLevelMigrationId",
(clojure.lang.IPersistentMap m) -> m.without("aliens")).removeFixedKeys("aliens")
))In this example you can see the fixed keys schema is being migrated by removing the "aliens" key, and the values of a subindexed map nested within are being migrated as well. Migration IDs are tracked per location and are used to determine what to do when a module is updated while it is still migrating values on disk, as described in the next section.
Updating a module mid-migration
You don’t need to wait for a migration to finish to update a module. If you leave the PState definition the same and don’t change any migration IDs, the migration will continue where it left off after the module update. However, if you change any migration IDs the entire migration will restart for the entire PState.
You might want to restart a migration for various reasons – you had a bug in your migration code, you want to tweak how you’re migrating those values, or you want to additionally migrate other parts of the PState.
For a restarted migration, some of the values seen by the migration function will have been migrated the first time around and some will not have been migrated yet. If you restart multiple times, there could be even more kinds of values. A restarted migration function must idempotently handle any of the kinds of values that could be seen.
Migration telemetry
Rama’s Cluster UI provides detailed information on migration progress. The main page and module page show if any migrations are still in-progress for any of their PStates:
The module instance page shows which PStates are in progress or done with migrations:
Diving into a PState page shows which partitions of that PState are still working on the migration:
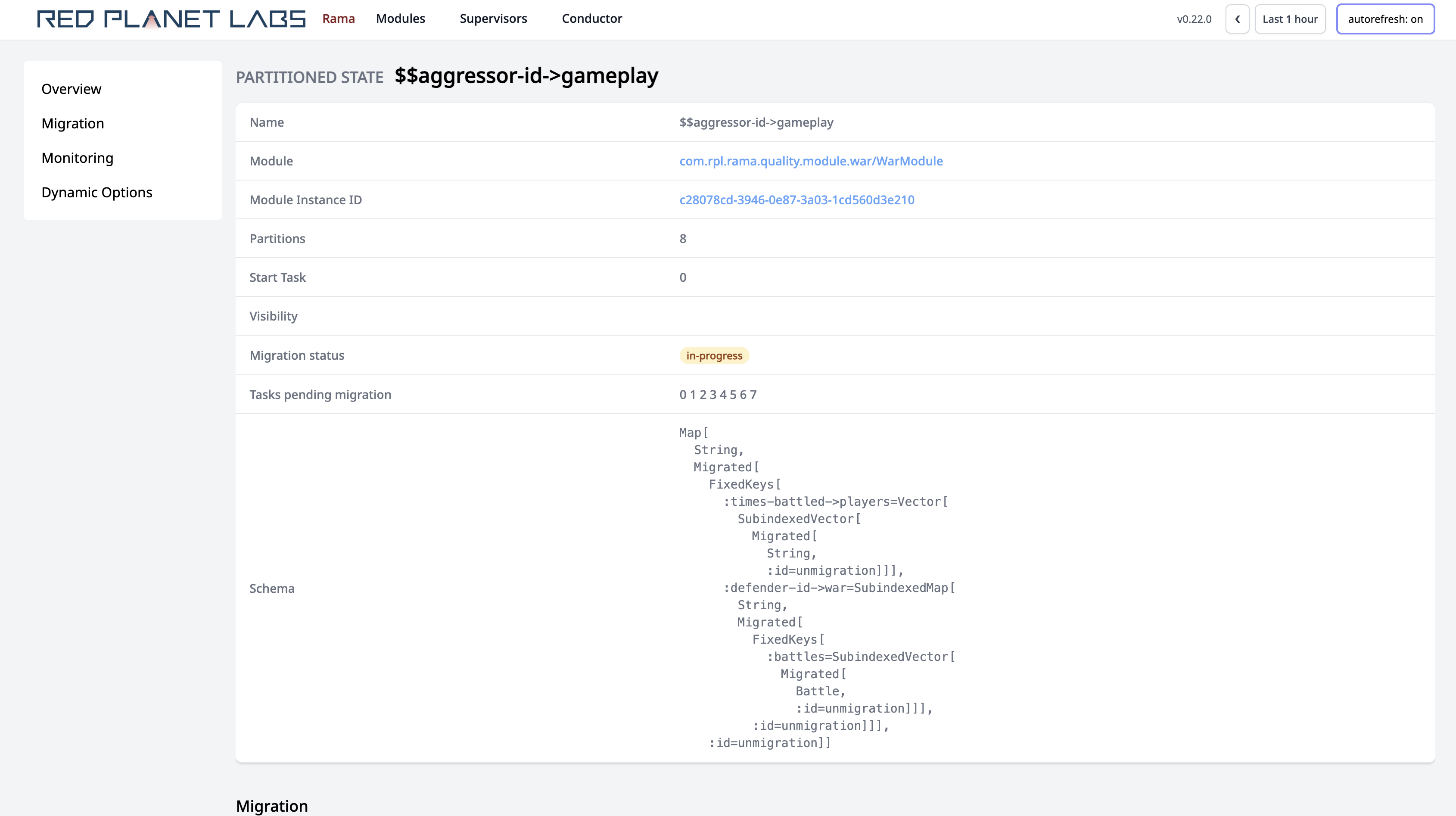
Scrolling below that shows time-series telemetry on the migration progress:
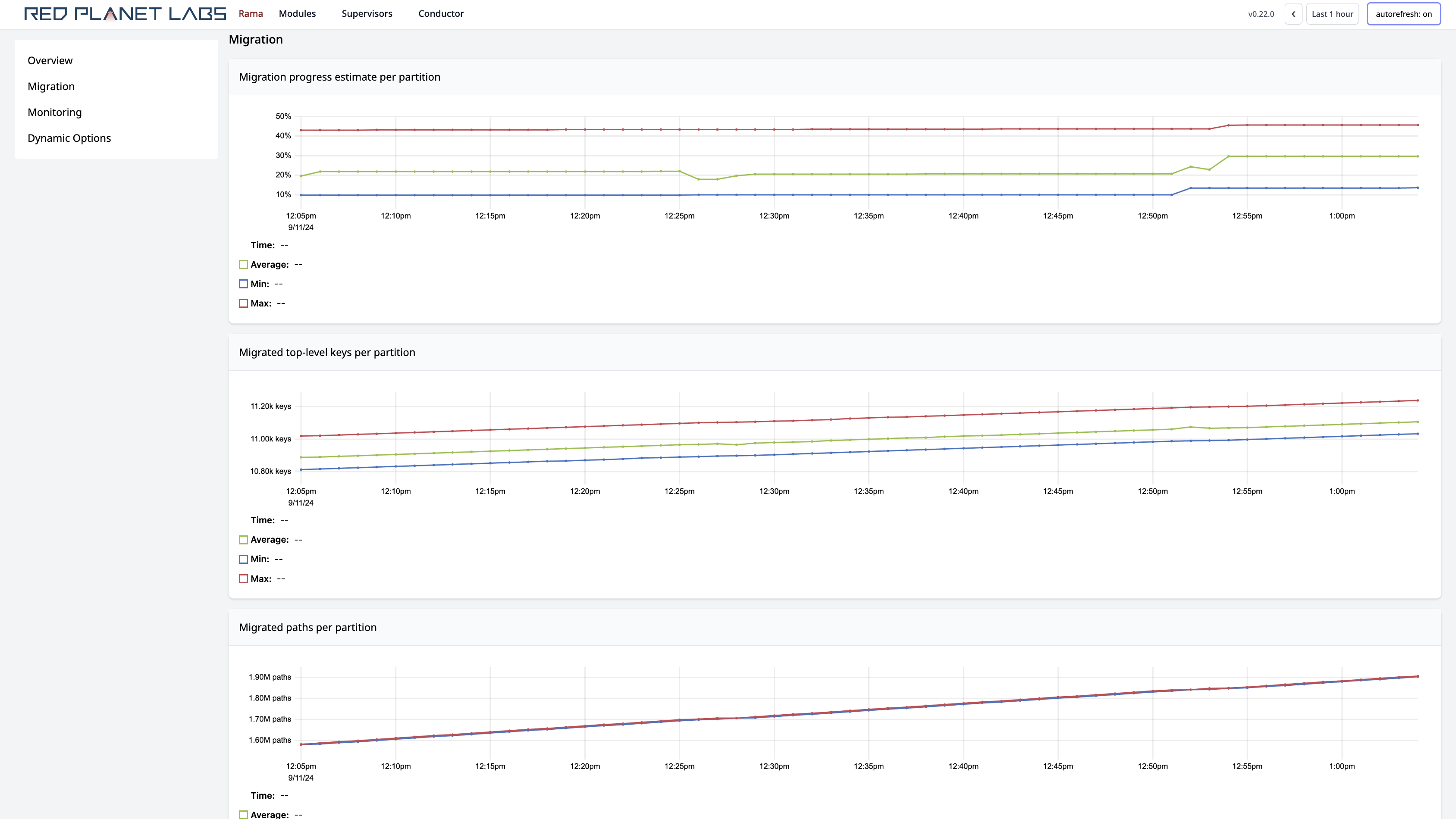
The first chart gives an estimate on the total progress of the migration based on the number of top-level keys that have had everything below them fully migrated versus the total number of top-level keys. It’s an estimate rather than an exact calculation because Rama only knows the approximate number of keys in a top-level map. The second chart shows the number of top-level keys that are fully migrated over time. The last chart shows the number of migration paths that have been applied to the PState. There could be many migration paths per top-level key if there are multiple values being migrated under a top-level key (e.g. all the values of a subindexed map nested within).
Completing a migration
When the Cluster UI shows a migration as complete for a PState, you’re free to remove the PState.migrated wrappers from the PState’s schema on the next module update. If you try to remove those before the migration is complete, Rama will reject the module update.
Controlling rate of migrations
Migrations happen as part of topology execution. Before each streaming batch or microbatch completes, a limited amount of migration work is done on a PState. If multiple PStates have migrations specified, the PStates are migrated one at a time. When a migration completes on a PState after some number of batches, it moves on to the next PState.
Each round of migration work iterates over part of the PState and applies transform paths to change and replicate the values on disk. The amount of iteration done in each round can be controlled by dynamic options. There are separate dynamic options for streaming and microbatching because they have different defaults:
-
topology.stream.migration.max.paths.per.batch: The maximum number of migration paths to apply in a single streaming batch -
topology.stream.migration.max.paths.per.second: The target number of migration paths to apply per second across all streaming batches -
topology.microbatch.migration.max.paths.per.batch: The maximum number of migration paths to apply in a single microbatch -
topology.microbatch.migration.max.paths.per.second: The target number of migration paths to apply per second across all microbatches
A migration uses additional task thread load, and the defaults increase task thread load by about 10% for common types of migrations. However, this can vary depending on the specifics of the migration, such as the cost of running the migration function.
If the module doesn’t have spare task thread load before the update, we recommend scaling the module first before deploying the migration.
Implicit migrations
Schema changes that are equivalent to or a generalization of that part of the PState schema can be done without declaring a formal migration on that location. These types of schema changes don’t cause any disk migration to be done in the background. For example, if the original PState schema is this:
s.pstate(
"$$p",
PState.mapSchema(
Integer.class,
Integer.class));You can do a module update with this schema without declaring a migration:
s.pstate(
"$$p",
PState.mapSchema(
Integer.class,
Object.class));Likewise, if your original PState schema is this:
s.pstate(
"$$p",
PState.mapSchema(
Integer.class,
Map.class));You can do an implicit migration like this:
s.pstate(
"$$p",
PState.mapSchema(
Integer.class,
PState.mapSchema(Object.class, Object.class)));On the other hand, trying to change that schema to this would be rejected:
s.pstate(
"$$p",
PState.mapSchema(
Integer.class,
PState.mapSchema(String.class, Object.class)));When Rama only knows the original type was Map.class, it can’t be migrated to a PState.mapSchema with anything other than Object.class keys and values since Rama doesn’t know what types were stored in those locations.
You can also migrate a location from PState.mapSchema with any key/value schemas to Map.class, as that is a generalization.
These examples were just for maps, but the same holds true for equivalent or generalized schemas for lists and sets as well.
Playing with migrations using IPC
You can try out migrations using in-process cluster (IPC). You can simulate multiple versions of the same module by overriding the getModuleName() method in the module definition. In a real project, the different versions of a module would be separated in version control, but to play with any sort of module update you’ll need both versions on the same classpath.
For example, here’s one version of a module:
public static class MyModuleV1 implements RamaModule {
@Override
public String getModuleName() { return "MyModule"; }
@Override
public void define(Setup setup, Topologies topologies) {
setup.declareDepot("*depot", Depot.hashBy(Ops.FIRST));
StreamTopology s = topologies.stream("s");
s.pstate("$$p", PState.mapSchema(String.class, Integer.class));
s.source("*depot").out("*tuple")
.each(Ops.EXPAND, "*tuple").out("*k", "*v")
.localTransform("$$p", Path.key("*k").termVal("*v"));
}
}Now suppose you want to update it to this version of the module along with a migration to the PState:
public static class MyModuleV2 implements RamaModule {
@Override
public String getModuleName() { return "MyModule"; }
@Override
public void define(Setup setup, Topologies topologies) {
setup.declareDepot("*depot", Depot.hashBy(Ops.FIRST));
StreamTopology s = topologies.stream("s");
s.pstate("$$p",
PState.mapSchema(
String.class,
PState.migrated(
String.class,
"myMigrationId",
(o) -> {
if(o instanceof String) return o;
else return "" + o + "!";
})));
s.source("*depot").out("*tuple")
.each(Ops.EXPAND, "*tuple").out("*k", "*v")
.each(Ops.TO_STRING, "*v", "!").out("*s")
.localTransform("$$p", Path.key("*k").termVal("*s"));
}
}The migration turns the number values in the PState into a string and appends a "!" to them. You can try out this migration in IPC like this:
try(InProcessCluster cluster = InProcessCluster.create()) {
RamaModule module = new MyModuleV1();
cluster.launchModule(module, new LaunchConfig(4, 2));
String moduleName = module.getModuleName();
Depot depot = cluster.clusterDepot(moduleName, "*depot");
PState p = cluster.clusterPState(moduleName, "$$p");
depot.append(Arrays.asList("a", 1));
depot.append(Arrays.asList("b", 2));
depot.append(Arrays.asList("c", 3));
System.out.println("a before update: " + p.selectOne(Path.key("a")));
System.out.println("b before update: " + p.selectOne(Path.key("b")));
System.out.println("c before update: " + p.selectOne(Path.key("c")));
cluster.updateModule(new MyModuleV2());
System.out.println("a after update: " + p.selectOne(Path.key("a")));
System.out.println("b after update: " + p.selectOne(Path.key("b")));
System.out.println("c after update: " + p.selectOne(Path.key("c")));
}This starts the first version of the module, appends some data, and then updates the module to the new version. It prints out the values of those keys before and after the update:
a before update: 1
b before update: 2
c before update: 3
a after update: 1!
b after update: 2!
c after update: 3!The "after update" values will print with the migration applied whether or not the migration has actually completed on disk yet.
Tuning options
Configurations
Here are the configurations available for PStates. Configurations for modules are fixed upon module deploy and can only be changed with a module update. They cannot be customized on a topology by topology basis. Likewise, configurations for clients also can only be changed by creating a new RamaClusterManager.
-
pstate.rocksdb.options.builder: PStates with a top-level map in the schema use RocksDB as the underlying durable storage. This config lets you provide the full name of a class implementing com.rpl.rama.RocksDBOptionsBuilder to configure the RocksDB instances. By default, RocksDB is configured to use two-level indexing and have a 256MB block cache. -
foreign.pstate.operation.timeout.millis: Timeout to use for foreign PState queries -
foreign.proxy.thread.pool.size: Size of the thread pool on PState clients to handleProxyStatecallbacks. -
foreign.proxy.failure.window.seconds: Length of window for which to count proxy failures to determine if it should be forcibly terminated -
foreign.proxy.failure.window.threshold: Number of failures within the failure window which will cause proxy to be forcibly terminated -
pstate.validate.subindexed.structure.locations: As explained above, this defaults to true and determines whether Rama will validate that subindexed structures aren’t moved. -
pstate.maximal.schema.validations: Also as explained above, this config defaults to true and determines whether schemas are checked completely on every write.
Dynamic options
Dynamic options can be edited from the Cluster UI and take effect immediately. They can be configured on a topology by topology basis. The dynamic options available for PStates are:
-
pstate.excessive.write.time.warning.millis: PState writes (calls tolocalTransform) that take longer than this threshold will be logged. -
pstate.reactivity.queue.limit: This puts a limit on the number of PState subscribers (fromproxycalls) that can be queued up for asynchronous diff processing. This option only applies to streaming PStates.localTransformcalls process subscribers synchronously with the transform up to a time limit, and any remaining subscribers are processed asynchronously so as not to hold the task thread excessively. When the limit is reached, those subscribers are dropped from processing that diff and will resync the next time they receive a diff. To avoid these resyncs, a module should be scaled to be able to handle the load of the number of expectedproxycalls. -
pstate.yielding.select.page.size: Controls default page size for selects using the.allowYield()option.
Summary
Building Rama applications largely revolves around determining how many PStates to create and what structure they should have. Rama makes it easy to make as few or as many PStates as you need.
The better you learn the Path API, the more you’ll get a feel for what kinds of PState structures work well for different kinds of situations. Paths are extremely flexible and expressive, and mastering them lets you see the full range of possibilities for what queries can be supported by any particular PState structure.
The availability of fine-grained reactive queries on PStates can also significantly impact how you design your overall application. They enable a level of reactive efficiency and interactivity which has never been possible before.