Paths
Paths are the core mechanism in Rama for reading and writing PStates. They provide a flexible and concise way to specify sophisticated, fine-grained behavior regardless of the complexity of a PState’s structure. The power of paths comes from being a composable abstraction. On this page you will learn:
-
How to think in terms of "navigators", the building blocks of paths.
-
The different kinds of navigators, including value navigators, virtual value navigators, filter navigators, substructure navigators, view navigators, and control navigators.
-
How to write your own navigators to handle custom types or different kinds of navigations.
All examples on this page can be found in the rama-examples project.
Navigation model
Paths navigate to locations in a data structure. A path is defined as a sequence of navigators, each of which specifies one step of navigation. Navigators and paths can navigate to one location, many locations, or even zero locations.
You can visualize navigation as "hopping" through a data structure. For example, suppose you’re working with a data structure that’s a map → map → lists, created with the following code. Since PStates are just data structures, we can use regular data structures as a substitute for exploring the capabilities of paths.
Map data = new HashMap() {{
put("a0", new HashMap() {{
put("a1", Arrays.asList(9, 3, 6));
put("b1", Arrays.asList(0, 8));
}});
put("b0", new HashMap() {{
put("c1", Arrays.asList("x", "y"));
}});
}};You can visualize this data structure like so:
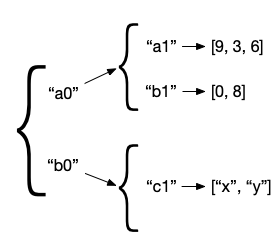
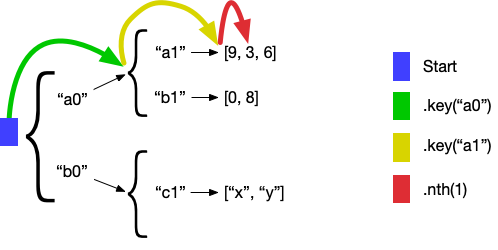
Let’s say you query this structure with the path Path.key("a0").key("a1").nth(1). Rama’s dataflow API can run select on regular data structures which is an easy way to experiment with paths without having to launch full modules. So you can run the following code:
Block.select(data, Path.key("a0").key("a1").nth(1)).out("*v")
.each(Ops.PRINTLN, "Val:", "*v")
.execute();In this case, the code prints:
Val: 3You can visualize the "hops" of this path like so:
|
A more convenient way to write this path is |
The key navigator navigates to the value for the specified key in a map, and the nth navigator navigates to the value for the specified index in a list.
Let’s take a look at another example that navigates to multiple values:
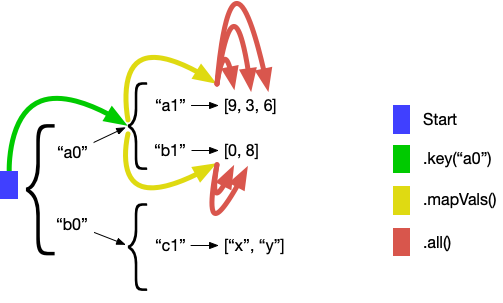
Block.select(data, Path.key("a0").mapVals().all()).out("*v")
.each(Ops.PRINTLN, "Val:", "*v")
.execute();The mapVals navigator navigates to each value of a map, and all navigates to each value of a list. To be clear, these navigators are navigating to each value individually. They are not navigating to a collection of values. So in this case, select navigates to five different values and emits one time for each value, printing the result:
Val: 9
Val: 3
Val: 6
Val: 0
Val: 8You can visualize this navigation like so:
It’s important to note select works differently in the dataflow API as in the PState client API (e.g. List results = pstate.select(Path.key("a0").mapVals().all())). The dataflow API emits to subsequent dataflow code, while the PState client API is called in a regular Java context. In the dataflow API, select emits one time per navigated value. Calling select on a PState client returns a list of all navigated values. So if the path navigates to zero values, the dataflow code will not emit while the PState client API will return an empty list. Paths themselves work exactly the same in both contexts – the only difference is how results are provided.
Let’s take a look at another path that includes filtering:
Block.select(data, Path.key("a0").mapVals().all().filterLessThan(7)).out("*v")
.each(Ops.PRINTLN, "Val:", "*v")
.execute();The filterLessThan navigator stays navigated at the current value if it is less than the specified number. This code prints:
Val: 3
Val: 6
Val: 0You can visualize this navigation as:
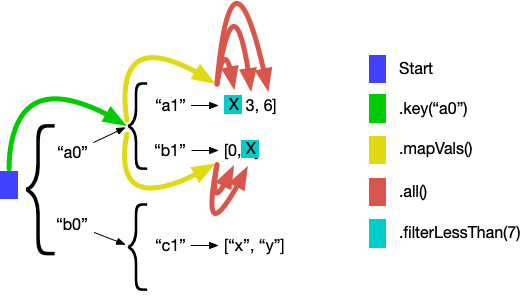
Whereas key, nth, mapVals, and all navigate to subvalues, filterLessThan does something different. It uses a condition to determine whether to continue navigating the path from that value or not.
With these three examples you should have the general feel for using paths. You use navigators to "hop" around a data structure to target the value or values that interest you. From the filterLessThan navigator you can see navigators don’t necessarily navigate to subvalues but can express different behavior. As a design principle navigators always perform one specific action, and you achieve more intricate behaviors through composing navigators together in arbitrary ways.
On the rest of this page, we’ll categorize the different kinds of navigators available. At the end of this page you’ll see the simple interface all navigators implement, and you’ll see how you can implement your own navigators using this interface.
Value navigators
"Value navigators" navigate to zero or more subvalues inside a data structure. Some value navigators always navigate to exactly one value (like key and nth), and sometimes the number of navigations depends on the data (like mapVals and all). You can group value navigators by the data structures on which they operate. Rama’s built-in value navigators support maps, sets, and lists. Rather than list every value navigator available, let’s explore a few of the interesting ones you haven’t seen yet to expand your mind to the possibilities. For a complete listing of navigators, consult the Javadoc for Path.
The first navigator navigates to the first element in a list. If the list is empty, it doesn’t navigate anywhere. For example, suppose you ran the following code on the same data we’ve been using:
Block.select(data, Path.key("b0", "c1").first()).out("*v")
.each(Ops.PRINTLN, "Val (A):", "*v")
.select(data, Path.key("z").first()).out("*v")
.each(Ops.PRINTLN, "Val (B):", "*v")
.execute();This prints:
Val (A): xNotice that since the key "z" does not exist in the top-level map, key("z") navigates to the value null. null is treated the same as an empty list for first, so no values are emitted from that second select call.
Next, let’s revisit all so you can see it works on data structures other than lists. Let’s take a look at using all on one of the inner maps in our example data:
Block.select(data, Path.key("a0").all()).out("*entry")
.each(Ops.PRINTLN, "Val:", "*entry")
.execute();This prints out:
Val: #object[java.util.HashMap$Node 0x142db18c a1=[9, 3, 6]]
Val: #object[java.util.HashMap$Node 0x4491644a b1=[0, 8]]Like how all on a list navigates to each value, all on a map navigates to each map entry (HashMap$Node is HashMap’s implementation of Map.Entry). Likewise, all also works on sets by navigating to each value. Conceptually all means to navigate to "all subvalues", and this concept is valid for many data structures.
Next, let’s take a look at the mapKey navigator. mapKey navigates to the specified key if it exists in the map. Note that it navigates to the key, not to the value for the key. You might be wondering why you would ever want to navigate to a key whose value you already have (since you’re providing the key as input to mapKey). And if you’re thinking in terms of select, you’re right that it’s not very useful. Where mapKey shows its utility is with PState transforms. Here’s an example of this using the TestPState utility to play with a transform path outside the context of a module:
try(TestPState tp = TestPState.create(Object.class)) {
Block.each(Ops.IDENTITY, tp).out("$$p")
.localTransform("$$p", Path.key("a").termVal(0))
.localTransform("$$p", Path.key("b").termVal(1))
.localSelect("$$p", Path.stay()).out("*initVal")
.each(Ops.PRINTLN, "Init:", "*initVal")
.localTransform("$$p", Path.mapKey("a").termVal("c"))
.localSelect("$$p", Path.stay()).out("*newVal")
.each(Ops.PRINTLN, "After transform:", "*newVal")
.execute();
}We’ll look at transforms in more depth later on this page, but this transform is simple enough to understand mapKey. The TestPState is initialized with some data and then another transform is performed with mapKey. The termVal navigator sets the value at that point of navigation to the specified value. Running this prints:
Init: {a 0, b 1}
After transform: {b 1, c 0}By navigating to the "a" key and changing its value to "c", the entire map entry is relocated to the "c" key. This is a much more concise way to perform the operation than the alternative of manually calling get, remove, and put on the map.
Value navigators encompass all the different ways of navigating to subvalues in data structures. With an understanding of value navigators now in place, let’s take a look at a similar category of navigators called "virtual value navigators".
Virtual value navigators
Whereas value navigators navigate to subvalues which currently exist in a data structure, virtual value navigators navigate to locations which don’t currently exist. Although this sounds like a wacky concept, virtual value navigators are quite useful for adding elements to nested data structures (as you often do with PStates). You’ve added elements to data structures a million times before, so virtual value navigators provide a brand new perspective on these kinds of operations.
Virtual value navigators have no use outside of transforms, so the examples in this section will all use TestPState. There are only a handful of virtual value navigators, so this section will look at all of them. Let’s start with the sole virtual value navigator for sets, voidSetElem:
try(TestPState tp = TestPState.create(Object.class)) {
Block.each(Ops.IDENTITY, tp).out("$$p")
.localTransform("$$p", Path.voidSetElem().termVal("a"))
.localSelect("$$p", Path.stay()).out("*v")
.each(Ops.PRINTLN, "After first transform:", "*v")
.localTransform("$$p", Path.voidSetElem().termVal("f"))
.localSelect("$$p", Path.stay()).out("*v")
.each(Ops.PRINTLN, "After second transform:", "*v")
.localTransform("$$p", Path.voidSetElem().termVal("c"))
.localSelect("$$p", Path.stay()).out("*v")
.each(Ops.PRINTLN, "After third transform:", "*v")
.execute();
}voidSetElem navigates to the "void" element for the set in question. The "void" element doesn’t currently exist in the set, and when it’s changed to an actual value becomes added to the set. So voidSetElem is a way to add elements to a set without ever needing to leave the context of a path. This is especially useful when dealing with sets nested inside other data structures, as it saves you quite a bit of code.
|
The |
Running this code prints:
After first transform: #{a}
After second transform: #{f a}
After third transform: #{f a c}Sets only have one way to add elements. Lists, on the other hand, can have elements added in a number of ways. So let’s take a look at the three virtual value navigators for lists: beforeElem, afterElem, and beforeIndex. Here’s an example utilizing all of them:
try(TestPState tp = TestPState.create(Object.class)) {
Block.each(Ops.IDENTITY, tp).out("$$p")
.localTransform("$$p", Path.afterElem().termVal("a"))
.localTransform("$$p", Path.afterElem().termVal("b"))
.localTransform("$$p", Path.afterElem().termVal("c"))
.localSelect("$$p", Path.stay()).out("*v")
.each(Ops.PRINTLN, "After appends:", "*v")
.localTransform("$$p", Path.beforeElem().termVal("d"))
.localSelect("$$p", Path.stay()).out("*v")
.each(Ops.PRINTLN, "After prepend:", "*v")
.localTransform("$$p", Path.beforeIndex(2).termVal("e"))
.localSelect("$$p", Path.stay()).out("*v")
.each(Ops.PRINTLN, "After insert:", "*v")
.execute();
}This code uses the three different virtual value navigators for lists. beforeElem navigates to the void element before the first element, afterElem navigates to the void element after the last element, and beforeIndex navigates to the void element in between the specified index and the prior index. In all these cases setting that void element to an actual value inserts a new element at that position. Using these virtual value navigators the code does three appends, one prepend, and one insertion before index 2. Running this prints:
After appends: (a b c)
After prepend: (d a b c)
After insert: (d a e b c)Virtual value navigators are a convenient way to express insertion of new elements into data structures, especially when those data structures are nested.
Filter navigators
Let’s now take a look at "filter navigators". You already saw one filter navigator, filterLessThan. All filter navigators determine whether to stay navigated at the current location or not. For all of these navigators you should think of "filter" as "filter for" – the navigator condition tests for what to keep and removes elements that don’t match the condition. Like before we won’t be looking at every navigator in this category, and you can consult the Javadoc for Path for the complete listing.
For the following examples, we’ll be using the same data as we used earlier in this page. As a reminder, the data structure looks like:
A commonly used filter navigator is filterPred, which runs a function on the navigated element. If the function returns false it stops navigation at that point. For example:
public static void filterPredExample() {
Map data = genData();
Block.select(data,
Path.mapVals()
.filterPred((Map m) -> m.size() == 1)
.mapVals()
.all()).out("*v")
.each(Ops.PRINTLN, "Val:", "*v")
.execute();
}The first .mapVals call navigates to two maps. The filterPred runs a function on each map to determine whether to continue navigating from that point. In this case, the function stays navigated only if the map has exactly one element. The map for the "a0" key has two elements, so the path stops navigating from that point. The map for the "b0" key matches the condition, so the path continues from there. Running this code prints:
Val: x
Val: yNotice that once navigation stops none of the subsequent navigators run for that element – this is what it means to stop navigation.
Here’s an example of the filterSelected navigator which does a nested select to determine whether to filter or not:
Block.select(data,
Path.mapVals()
.filterSelected(Path.mapVals().all().filterEqual(8))
.key("a1")
.all()).out("*v")
.each(Ops.PRINTLN, "Val:", "*v")
.execute();This prints:
Val: 9
Val: 3
Val: 6This is the first navigator you’ve seen making use of a subpath. In this case, filterSelected checks whether that subpath selects anything from that point. If not, it stops navigation. There are two things to note here:
-
filterSelecteddoes not navigate anywhere. If thefilterSelectedcondition passes it’s navigated at the same location as before the condition ran. -
The condition has nothing to do with the values navigated to by the path. The condition is purely based on whether it navigated to any locations at all. So if it navigated to one, two, or ten locations, the condition passes. if it navigates to zero locations, the condition fails and it stops navigation.
Filter navigators are one form of navigator that conditions its behavior based on the value currently navigated to. You’ll see even more conditional kinds of behavior in the section below on "control navigators".
Substructure navigators
Substructure navigators are one of the most powerful categories of navigators. When used in transforms, you can do some mind-bending manipulations in a surprisingly small amount of code. You don’t need substructure navigators very often for transforms, but when you do you feel like a wizard.
Most data structures can be broken up into smaller versions containing less data. A set can be broken up into any number of subsets, a map into submaps, and a list into sublists. A substructure navigator navigates to one of these smaller versions, and transforms to those substructures affect the original locations in the parent data structure. Let’s look at some examples.
subList and filteredList
subList, as the name implies, navigates to a contiguous part of a list. For example, consider the following code run on the same data we’ve been using:
Block.select(data, Path.key("a0", "a1").sublist(1, 3))
.execute();This selects the sublist from indices 1 (inclusive) to 3 (exclusive), printing:
Val: [3 6]That’s useful but not very exciting. Now let’s take a look at using subList inside a transform. In this code we’ll initialize a TestPState with some data and then use subList to reverse part of a nested list:
try(TestPState tp = TestPState.create(Object.class)) {
Block.each(Ops.IDENTITY, tp).out("$$p")
.localTransform("$$p", Path.key("k").afterElem().termVal("a"))
.localTransform("$$p", Path.key("k").afterElem().termVal("b"))
.localTransform("$$p", Path.key("k").afterElem().termVal("c"))
.localTransform("$$p", Path.key("k").afterElem().termVal("d"))
.localTransform("$$p", Path.key("k").afterElem().termVal("e"))
.localTransform("$$p", Path.key("k").afterElem().termVal("f"))
.localSelect("$$p", Path.key("k")).out("*v")
.each(Ops.PRINTLN, "Initial nested list:", "*v")
.localTransform("$$p",
Path.key("k")
.sublist(1, 5)
.term((List l) -> {
List ret = new ArrayList(l);
Collections.reverse(ret);
return ret;
}))
.localSelect("$$p", Path.key("k")).out("*v")
.each(Ops.PRINTLN, "After transform:", "*v")
.execute();
}The code first initializes a list for key "k" with six elements. It then does another transform using subList to reverse the order of the middle four elements of that list. This code prints:
Initial nested list: (a b c d e f)
After transform: (a e d c b f)A few notes about this code:
-
termis used for one of the transform paths. UnliketermValwhich replaces the navigated value with the provided value,termreplaces the navigated value with the results of running the provided function on the navigated value. In this case, it returns a new list computed to be the reverse of the input list. -
You may be wondering why the
termfunction creates a brand new list. This is because the input list is immutable and cannot be modified.subListalways navigates to immutable lists.
This usage of subList demonstrates a computation which can be tricky to write manually. But with the power of paths and composition, it’s easy.
Let’s take a look at another substructure navigator for lists: filteredList. Like filterSelected, this takes in a condition path as input. filteredList navigates to a list of all elements matching the specified condition path. Here’s an example that reverses all the even numbers in a list:
try(TestPState tp = TestPState.create(Object.class)) {
Block.each(Ops.IDENTITY, tp).out("$$p")
.localTransform("$$p", Path.afterElem().termVal(0))
.localTransform("$$p", Path.afterElem().termVal(1))
.localTransform("$$p", Path.afterElem().termVal(2))
.localTransform("$$p", Path.afterElem().termVal(3))
.localTransform("$$p", Path.afterElem().termVal(4))
.localTransform("$$p", Path.afterElem().termVal(5))
.localSelect("$$p", Path.stay()).out("*v")
.each(Ops.PRINTLN, "Initial list:", "*v")
.localTransform("$$p",
Path.filteredList(Path.filterPred(Ops.IS_EVEN))
.term((List l) -> {
List ret = new ArrayList(l);
Collections.reverse(ret);
return ret;
}))
.localSelect("$$p", Path.stay()).out("*v")
.each(Ops.PRINTLN, "After transform:", "*v")
.execute();
}Like previous examples, this initializes a list of numbers into the TestPState and then runs a transform using filteredList. Running this prints:
Initial list: (0 1 2 3 4 5)
After transform: (4 1 2 3 0 5)As you can see from this example, filteredList remembers the positions each element corresponds to in the original list. So when the sublist is reversed, the positions are reversed back in the original list.
Reversing sublists, whether contiguous or not, is probably not something you’ll ever need to do. But the point of these examples is to show the extremely precise control you have over how you query and manipulate data structures. To write these kinds of manipulations using regular Java code requires far more effort. Since PStates are just data structures, oftentimes nested, paths give you extremely precise control over how you index your data.
Range queries
Let’s look at two more examples of substructure navigators: sortedMapRange and sortedMapRangeFrom. These navigators, alongside the similar navigators sortedSetRange and sortedSetRangeFrom, are how you do range queries in Rama. Top-level and subindexed maps in PStates are sorted, and these navigators are how you efficiently iterate over portions of those indexes. For instance, you may be storing ten years of time-series information in a subindexed map and only want to fetch a few minutes from it.
Because it’s such a common use case, let’s take a look at using these navigators with a module storing time-series data. In this example, the "*purchaseDepot" receives purchase information consisting of a store ID, a product ID, the "minute bucket" when the purchase was made, and a dollar amount. The module materializes the "$$totalsByTime" PState with the following structure:
{storeId<String>: {productId<String>: {minuteBucket<Long>: revenue<Long>}}}The inner two maps are subindexed since they can contain a lot of elements. Here’s the code:
public class SortedMapRangeModule implements RamaModule {
@Override
public void define(Setup setup, Topologies topologies) {
setup.declareDepot("*purchaseDepot", Depot.hashBy(Ops.FIRST));
StreamTopology s = topologies.stream("products");
s.pstate(
"$$totalsByTime",
PState.mapSchema(
String.class,
PState.mapSchema(
String.class,
PState.mapSchema(Integer.class, Long.class).subindexed()
).subindexed()));
s.source("*purchaseDepot").out("*tuple")
.each(Ops.EXPAND, "*tuple").out("*storeId", "*productId", "*minuteBucket", "*amt")
.compoundAgg(
"$$totalsByTime",
CompoundAgg.map(
"*storeId",
CompoundAgg.map(
"*productId",
CompoundAgg.map(
"*minuteBucket",
Agg.sum("*amt")))));
}
public static void main(String[] args) throws Exception {
try(InProcessCluster cluster = InProcessCluster.create()) {
RamaModule module = new SortedMapRangeModule();
cluster.launchModule(module, new LaunchConfig(4, 2));
String moduleName = module.getClass().getName();
Depot purchaseDepot = cluster.clusterDepot(moduleName, "*purchaseDepot");
PState totalsByTime = cluster.clusterPState(moduleName, "$$totalsByTime");
purchaseDepot.append(Arrays.asList("blockbuster", "witness-for-the-prosecution", 10, 3));
purchaseDepot.append(Arrays.asList("blockbuster", "witness-for-the-prosecution", 10, 11));
purchaseDepot.append(Arrays.asList("blockbuster", "witness-for-the-prosecution", 11, 12));
purchaseDepot.append(Arrays.asList("blockbuster", "witness-for-the-prosecution", 15, 4));
purchaseDepot.append(Arrays.asList("blockbuster", "witness-for-the-prosecution", 16, 17));
purchaseDepot.append(Arrays.asList("blockbuster", "all-about-eve", 10, 1));
purchaseDepot.append(Arrays.asList("blockbuster", "stangers-on-a-train", 11, 9));
purchaseDepot.append(Arrays.asList("blockbuster", "the-best-years-of-our-lives", 10, 3));
purchaseDepot.append(Arrays.asList("blockbuster", "inherit-the-wind", 10, 4));
purchaseDepot.append(Arrays.asList("blockbuster", "paths-of-glory", 12, 5));
System.out.println(
"Query 1: " +
totalsByTime.select(Path.key("blockbuster", "witness-for-the-prosecution")
.sortedMapRange(10, 20)
.all()
.filterSelected(Path.last().filterGreaterThan(10))));
System.out.println(
"Query 2: " +
totalsByTime.select(Path.key("blockbuster").sortedMapRangeFrom("", 5).mapKeys()));
}
}
}Before explaining the code, let’s take a look at the results of running main:
Query 1: [[10 14] [11 12] [16 17]]
Query 2: ["all-about-eve" "inherit-the-wind" "paths-of-glory" "stangers-on-a-train" "the-best-years-of-our-lives"]The module here is extremely simple. It processes purchase data as lists containing four elements and uses Ops.EXPAND to bind each of those four elements to vars. It then aggregates into "$$totalsByTime" the number of dollars received for each product for each time bucket.
In the main method, some test data is appended to the module. Then you can see the two queries making use of the range query navigators. The first query uses sortedMapRange which gets the submap from a start key (inclusive) to an end key (exclusive). The query fetches the time buckets in that range for that product that received more than $10.
The second query uses sortedMapRangeFrom to get the first five products indexed in the product map for the store "blockbuster". sortedMapRangeFrom takes in a start key and a maximum number of elements to read from that point. sortedMapRangeFrom is useful when you want to read a fixed size range of data. It is frequently used for paginating through large amounts of data, where each page is a fixed size. In this case "" is the smallest possible string so this gets the submap with the first five entries in that products map. Since this query is only interested in the product names, it uses mapKeys to make sure only those are returned.
In all PState queries, the paths execute entirely server side. So the only data returned is the results of executing the path. Since paths are so expressive, including having the ability to make use of arbitrary Java functions, you have heaps of computational power out your disposal when it comes to querying your indexes.
The variants of the range query navigators you’ve seen always include the start key in the results, and for sortedMapRange and sortedSetRange, exclude the end key. There are other variants of these navigators which accept options that let you specify explicitly whether the start or end keys are inclusive or exclusive. See the Javadoc for more detail.
There are many other substructure navigators available. Be sure to check out the Javadoc for Path for a complete listing.
View navigators
Another category of navigators is "view navigators". View navigators navigate you to a transformation of the currently navigated value.
The simplest view navigator is nullToVal. This navigator navigates to the provided value if the current navigated value is null and does nothing otherwise. For example:
Map data = new HashMap();
data.put("a", 1);
Block.select(data, Path.key("a").nullToVal("xyz")).out("*v")
.each(Ops.PRINTLN, "Val 1:", "*v")
.select(data, Path.key("b").nullToVal("xyz")).out("*v")
.each(Ops.PRINTLN, "Val 2:", "*v")
.execute();This prints:
Val 1: 1
Val 2: xyzAs you can see, since the value for the "a" key is non-null, nullToVal does nothing. But since the value for the "b" key is null, it navigates to the provided value "xyz".
nullToVal is commonly used to initialize a new value when doing a nested transform. It’s less commonly used for selects, though it can occasionally be a convenience for those use cases.
A more interesting view navigator is view. view is extremely generic – it changes the navigated value by running any Java code you want. Here are some examples:
public static class MyFunction implements RamaFunction1<List, String> {
private String token;
public MyFunction(String token) {
this.token = token;
}
@Override
public String invoke(List l) {
return "" + l.size() + "/" + token + "/" + l.get(0);
}
}
public static void viewExamples() {
Map data = new HashMap();
data.put("a", Arrays.asList(1, 5, 10));
Block.select(data, Path.key("a").nth(0).view(Ops.INC)).out("*v")
.each(Ops.PRINTLN, "Val 1:", "*v")
.select(data, Path.key("a").view((List l) -> l.size() + 10)).out("*v")
.each(Ops.PRINTLN, "Val 2:", "*v")
.select(data, Path.key("a").view(new MyFunction("***"))).out("*v")
.each(Ops.PRINTLN, "Val 3:", "*v")
.execute();
}Running viewExamples prints:
Val 1: 2
Val 2: 13
Val 3: 3/***/1From these examples you can see view can take in any function as input, whether a predefined function in Rama from the Ops class, Java lambdas, or explicit implementations of the RamaFunction1 interface.
While you get this level of flexibility when using view in dataflow code, there are some restrictions when using select on a PState from a client. Rama requires that any functions sent to modules as part of queries already exist on that module’s classpath. So in the above examples the usages of Ops.INC and MyFunction would work fine (as long as MyFunction is on the module’s classpath), but the lambda would not (it would be a huge security risk if Rama let you execute arbitrary foreign code like this inside of modules!).
As a module writer, you can include custom functions for clients to make use of in their PState queries. These functions serve a similar purpose as "user defined functions" in SQL databases, except they’re written in regular Java code instead of a limited DSL. Because they’re written in regular Java code, you can make use of the full power of the Java ecosystem.
Let’s take a look at one more view navigator: transformed. transformed works just like view except expresses how the value is changed with a transform path instead of a Java function. For example:
Map data = new HashMap();
data.put("a", Arrays.asList(1, 5, 10));
Block.select(data, Path.key("a").transformed(Path.nth(1).termVal("!"))).out("*v")
.each(Ops.PRINTLN, "Val:", "*v")
.execute();This prints:
Val: (1 ! 10)transformed is another good example of a navigator that’s parameterized with a path. It’s useful when you want part of the values you’re selecting to be in a different form.
Control navigators
The final category of navigators to explore are "control navigators". These manipulate the flow of navigation, similar to how operators like if and or manipulate program flow in regular programming.
The most basic control navigators are stay and stop. As their names imply, the former does nothing and the latter stops navigation. For example:
Map data = new HashMap();
data.put("a", 1);
Block.select(data, Path.key("a").stay()).out("*v")
.each(Ops.PRINTLN, "Val 1:", "*v")
.select(data, Path.key("a").stop()).out("*v")
.each(Ops.PRINTLN, "Val 2:", "*v")
.execute();This prints:
Val 1: 1stay and stop are not navigators you usually use on their own. Their use would be in other control navigators or in Java functions which build paths dynamically.
Let’s now take a look at ifPath. ifPath branches navigation based on the results of a condition. Like filterSelected, the condition for ifPath is a path and tests whether that path navigates to any locations. For example:
Map data = new HashMap();
data.put("a", Arrays.asList(1, 5, 10));
Block.select(
data,
Path.key("a")
.ifPath(Path.nth(0).filterEqual(1),
Path.nth(1),
Path.nth(2))).out("*v")
.each(Ops.PRINTLN, "Val 1:", "*v")
.select(
data,
Path.key("a")
.ifPath(Path.all().filterEqual("x"),
Path.nth(1),
Path.nth(2))).out("*v")
.each(Ops.PRINTLN, "Val 2:", "*v")
.select(
data,
Path.key("a")
.ifPath(Path.stop(), Path.stay())
.nth(0)).out("*v")
.each(Ops.PRINTLN, "Val 3:", "*v")
.execute();This prints:
Val 1: 5
Val 2: 10All these usages of ifPath navigate to the nested list and branch the path based on the value of that list. In the first case, it tests whether the first element of the list is equal to 1. If so it navigates to index 1, and if not it navigates to index 2. In this case the condition passes so it navigates to index 1.
In the second case, the condition path tests whether any elements in the list are equal to "x". Since that path fails to navigate to any locations, navigation continues down the "else" path by navigating to index 2.
In the last case, you can see what happens when you don’t provide an "else" path. When not provided the "else" path is equivalent to Path.stop(), The condition path Path.stop() always fails, so it uses that default path and stops navigation. This is why "Val 3" isn’t printed.
Let’s now take a look at multiPath. multiPath continues navigation from the given point down multiple paths. For example:
Map data = new HashMap();
data.put("a", 1);
data.put("b", 2);
data.put("c", 3);
Block.select(data, Path.multiPath(Path.key("a"), Path.key("b"))).out("*v")
.each(Ops.PRINTLN, "Val:", "*v")
.execute();This prints:
Val: 1
Val: 2As you can see, the effect of this path is to navigate to both the "a" and "b" keys. multiPath always traverses the paths in the order in which you provide them. In this case, for example, that property lets you know the first result is the value for "a" and the second the value for "b".
When used within a condition path (e.g. for ifPath or filterSelected), multiPath is like an or operator. Since a condition path is "true" if it navigates to any location, multiPath is "true" if either path navigates to any location.
The last control navigator we’ll look at is subselect. In a way subselect could also be considered a substructure navigator. When used inside of transforms subselect can do some truly mind-bending things.
Let’s start with an example of using subselect inside a select:
Map data = new HashMap();
data.put("a", Arrays.asList(1, 2, 3));
data.put("b", Arrays.asList(4, 5));
Block.select(data, Path.mapVals().subselect(Path.all().filterPred(Ops.IS_ODD))).out("*v")
.each(Ops.PRINTLN, "Val:", "*v")
.execute();This prints:
Val: [1 3]
Val: [5]subselect acts like a select inside the overall path and navigates to a list of values. From this example, you can see it executes a nested select from each of the map vals.
subselect gets interesting inside of transforms since it remembers the original locations of all navigated values. So when you modify the list navigated to by subselect, the original locations of all those values are modified in the original data structure. Let’s look at an example:
try(TestPState tp = TestPState.create(Object.class)) {
Block.each(Ops.IDENTITY, tp).out("$$p")
.localTransform("$$p", Path.afterElem().termVal(null))
.localTransform("$$p", Path.last().afterElem().termVal(1))
.localTransform("$$p", Path.last().afterElem().termVal(2))
.localTransform("$$p", Path.last().afterElem().termVal(3))
.localTransform("$$p", Path.last().afterElem().termVal(4))
.localTransform("$$p", Path.afterElem().termVal(null))
.localTransform("$$p", Path.last().afterElem().termVal(5))
.localTransform("$$p", Path.last().afterElem().termVal(6))
.localTransform("$$p", Path.last().afterElem().termVal(7))
.localTransform("$$p", Path.afterElem().termVal(null))
.localTransform("$$p", Path.last().afterElem().termVal(8))
.localTransform("$$p", Path.last().afterElem().termVal(9))
.localTransform("$$p", Path.last().afterElem().termVal(10))
.localSelect("$$p", Path.stay()).out("*v")
.each(Ops.PRINTLN, "Initial contents:", "*v")
.localTransform("$$p",
Path.subselect(Path.all().all().filterPred(Ops.IS_ODD))
.term((List l) -> {
List ret = new ArrayList(l);
Collections.reverse(ret);
return ret;
}))
.localSelect("$$p", Path.stay()).out("*v")
.each(Ops.PRINTLN, "After transform:", "*v")
.execute();
}The TestPState is initialized with a list of lists of numbers. Then a transform is done using subselect to reverse the positions of the odd numbers across all lists. Running this prints:
Initial contents: ((1 2 3 4) (5 6 7) (8 9 10))
After transform: ((9 2 7 4) (5 6 3) (8 1 10))It doesn’t matter how deep subselect reaches during its selection. It remembers the locations of all selected values and can do mind-bending manipulations like this. These are the kinds of manipulations which are very difficult to code manually, yet with paths they’re expressed in a tiny amount of code.
You’re unlikely to come across many use cases which require manipulation like this. But subselect, more than any other navigator, demonstrates the awesome power you have at your disposal for slicing and dicing your PStates any which way you wish.
subselect does have many important uses during client PState selects – you saw a usage of it in the tutorial. Whenever you want your query to perform aggregation of multiple selected values as part of your path, like a sum, subselect is your tool.
Transform paths
You’ve seen a number of examples already on this page of using paths in localTransform operations, but let’s now take a deeper look at how they work.
|
Paths used in transforms only work on:
The built-in navigators are oriented towards immutable data structures, so they won’t work on mutable Java types like Paths used for selects work fine on Java’s mutable data structures. |
Paths in localTransform work exactly like they do in select – using a path you specify the subvalues you wish to change by navigating to them. The only difference is all navigation in a localTransform must end in one of the special "term" navigators. These are:
-
termVal: Replace the navigated value with the provided value. -
term: Replace the navigated value with the result of running a function on it. -
termVoid: Replace the navigated value with "void", having the effect of removing it from the collection it’s within.termVoidis only valid when the value exists within a collection and does not work for top-level values.
If navigation does not end in one of the "term" navigators, you’ll get an exception at runtime.
You’ve already seen many examples of using termVal, so we don’t need to explore that further. You’ve seen some examples of term, but there’s additional capabilities there worth looking at.
term allows you to specify up to seven additional arguments which will be passed in to the provided function along with the navigated value. This feature is purely a convenience. For example:
try(TestPState tp = TestPState.create(Object.class)) {
Block.each(Ops.IDENTITY, tp).out("$$p")
.localTransform("$$p", Path.key("a").termVal(1))
.localTransform("$$p", Path.key("b").termVal(2))
.localSelect("$$p", Path.stay()).out("*v")
.each(Ops.PRINTLN, "Initial value:", "*v")
.localTransform("$$p", Path.key("a").term(Ops.PLUS, 10))
.localTransform("$$p",
Path.key("b")
.term((Integer v, Integer arg1, Integer arg2) -> {
System.out.println("term function args: " + v + ", " + arg1 + ", " + arg2);
return v * arg1 + arg2;
}, 10, 20))
.localSelect("$$p", Path.stay()).out("*v")
.each(Ops.PRINTLN, "After transforms:", "*v")
.execute();
}This prints:
Initial value: {a 1, b 2}
term function args: 2, 10, 20
After transforms: {a 11, b 40}If term didn’t accept any extra arguments, you could achieve the same thing by defining RamaFunction1 implementations that take the extra arguments in the constructor and them as instance fields. This feature of term lets you avoid the hassle of defining those extra classes, making a use case like adding 10 to the navigated value trivial. You can see from the output here how the term function takes in the navigated value first followed by the additional arguments.
Let’s now take a look at termVoid. Whereas navigators like afterElem can add new elements to a list by navigating to a "void" element, termVoid does the opposite by setting an existing value to "void". This causes that element to be removed from the data structure. Let’s look at some examples:
try(TestPState tp = TestPState.create(Object.class)) {
Block.each(Ops.IDENTITY, tp).out("$$p")
.localTransform("$$p", Path.key("a").afterElem().termVal(1))
.localTransform("$$p", Path.key("a").afterElem().termVal(2))
.localTransform("$$p", Path.key("a").afterElem().termVal(3))
.localTransform("$$p", Path.key("b").termVal("xyz"))
.localSelect("$$p", Path.stay()).out("*v")
.each(Ops.PRINTLN, "Initial value:", "*v")
.localTransform("$$p", Path.key("a").nth(1).termVoid())
.localTransform("$$p", Path.key("b").termVoid())
.localSelect("$$p", Path.stay()).out("*v")
.each(Ops.PRINTLN, "After transforms:", "*v")
.execute();
}Running this prints:
Initial value: {a (1 2 3), b xyz}
After transforms: {a (1 3)}With termVoid it doesn’t matter how you navigate to the element you wish to remove. When you set it to "void" the element will be removed.
Custom navigators
The built-in navigators are so expressive you’ll find the need to write your own custom navigators a rare occurrence. If you’re using custom types inside of PStates and you want to slice and dice them in a fine-grained way with paths, then implementing your own navigators would be appropriate.
Custom navigators just have to implement the following interface:
public interface Navigator<T> extends RamaSerializable {
Object VOID = new Object();
interface Next {
Object invokeNext(Object obj);
}
Object select(T obj, Next next);
T transform(T obj, Next next);
}This is the same interface used to implement every navigator provided by Rama. Isn’t it amazing how the incredible expressiveness of paths is powered by such a simple interface?
To explain this interface, let’s take a look at how you would implement a navigator that navigates to the first two elements of a list. If the list has less than two elements, the navigator stops navigation. Here’s the code:
public class MyListNav implements Navigator<List> {
@Override
public Object select(List obj, Next next) {
if(obj.size() < 2) return Navigator.VOID;
else {
Object ret = next.invokeNext(obj.get(0));
next.invokeNext(obj.get(1));
return ret;
}
}
@Override
public List transform(List obj, Next next) {
if(obj.size() >= 2) {
Object new0 = next.invokeNext(obj.get(0));
Object new1 = next.invokeNext(obj.get(1));
if(new1 == Navigator.VOID) obj.remove(1);
else obj.set(1, new1);
if(new0 == Navigator.VOID) obj.remove(0);
else obj.set(0, new0);
}
return obj;
}
}The select method must:
-
Call
next.invokeNexton any values to navigate to.next.invokeNextcontinues executing the rest of the path in which the navigator instance lives. -
Return Navigator.VOID if there are no values to navigate to.
-
If the method navigates to any values, it must return the result of calling
next.invokeNexton the first navigated value.
In this case, the select implementation checks the list has at least two elements. If not, it returns Navigator.VOID to indicate navigation is stopped. Otherwise, it continues navigation to the first two elements of the list and returns the first result.
The transform method must:
-
Call
next.invokeNexton navigated values to compute their new values. -
Replace navigated values with their replacement values from
next.invokeNext. -
Return the fully updated data structure.
In this case, the transform implementation checks the list has enough elements. If not, it returns the list unchanged. Otherwise, it uses next.invokeNext to compute the new values of indexes 0 and 1. So that this navigator supports removal of those elements, it checks whether the navigated values transformed to Navigator.VOID. If they did, they are removed from the list instead of updated.
|
This navigator only works on mutable lists, while the lists/maps/sets used in Rama are generally immutable objects. So you wouldn’t be able to mutate them in this way. But if you were storing a mutable list type as a value in a PState, then this navigator would work on those values. |
Finally, to use this navigator in a path you use either the customNav or customNavBuilder methods on Path. customNav receives a Navigator as an argument directly, while customNavBuilder receives a function that returns a dynamically constructed Navigator object. First, here’s an example of customNav:
List data1 = new ArrayList();
data1.add(10);
data1.add(11);
data1.add(12);
List data2 = new ArrayList();
data2.add(1);
Block.select(data1, Path.customNav(new MyListNav())).out("*v")
.each(Ops.PRINTLN, "Val 1:", "*v")
.select(data2, Path.customNav(new MyListNav())).out("*v")
.each(Ops.PRINTLN, "Val 2:", "*v")
.execute();This prints:
Val 1: 10
Val 1: 11As you can see, the first select navigates to the first two elements of data1 while the second select navigates nowhere because data2 has less than two elements.
Let’s now take a look at using customNavBuilder to construct a Navigator object dynamically using the values of vars at runtime. The example will use the following Navigator which navigates to a key in a map (about equivalent to the key navigator):
public class CustomKey implements Navigator<Map> {
private final Object _k;
public CustomKey(Object k) {
_k = k;
}
@Override
public Object select(Map obj, Next next) {
return next.invokeNext(obj.get(_k));
}
@Override
public Map transform(Map obj, Next next) {
obj.put(_k, next.invokeNext(obj.get(_k)));
return obj;
}
}Here’s an example of constructing instances of this Navigator dynamically using customNavBuilder:
Map data = new HashMap();
data.put("a", 1);
data.put("bc", 2);
Block.select(data,
Path.customNavBuilder((String k) -> new CustomKey(k), "a")).out("*v")
.each(Ops.PRINTLN, "Val 1:", "*v")
.select(data,
Path.customNavBuilder(
(String arg1, String arg2) -> new CustomKey(arg1 + arg2),
"b", "c")).out("*v")
.each(Ops.PRINTLN, "Val 2:", "*v")
.execute();Running this prints:
Val 1: 1
Val 2: 2customNavBuilder allows you to make use of the values of vars when constructing Navigator objects, such as values coming from depot records or selected from PStates. The first argument to customNavBuilder is the builder function, and subsequent arguments are passed into that function at runtime (similar to how Block#each works).
Value collection
Paths have another feature called "value collection" that works alongside navigation. These special methods let you collect and manipulate a list of values that’s maintained on the side. If you collect any values, those are returned alongside navigated values during select calls. For example:
Map data = new HashMap();
data.put("a", 1);
data.put("b", 2);
Block.select(data,
Path.collectOne(Path.key("b"))
.key("a")).out("*v")
.each(Ops.PRINTLN, "Val:", "*v")
.execute();This prints:
Val: [2 1]collectOne adds a single value to the special list of collected values. It requires the provided path to navigate to exactly one value. You can see here that because of the collected value, the result of select is a list rather than just the navigated value 1. When Rama sees any values are collected, it adds the navigated value to the end of the special list to produce the result.
Value collection allows you to capture additional information along the route of navigation that are stored as parents or cousins to the values you navigate to. For example, you can use value collection to capture map keys as you traverse into their values.
Here’s another example making use of the other value collectors collect and putCollected:
Map data = new HashMap();
data.put("a", 1);
data.put("b", 2);
Block.select(data,
Path.collect(Path.mapKeys())
.multiPath(Path.key("a"), Path.key("b"))
.putCollected("xyz")
.collectOne(Path.stay())).out("*v")
.each(Ops.PRINTLN, "Val:", "*v")
.execute();This prints:
Val: [[a b] xyz 1 1]
Val: [[a b] xyz 2 2]As you can see here, collect adds a list of navigated values to the collected values list. putCollected adds the provided value to the collected values. You should also notice here that collected values are independent across every branch of navigation. Collected values will be shared until there’s a branch, and then each branch will add to their own collected values list.
The last two special methods having to do with value collection are dispenseCollected and isCollected. dispenseCollected clears the collected values list from that point on in navigation. It is only useful alongside isCollected, which works like a filter navigator except it takes the list of collected values as input rather than the navigated value. So one pattern you might use is to use value collection to collect information for the purpose of using isCollected as a filter navigator, and then you dispose all the collected values afterwards.
Reactivity
The reactive query functions proxy and proxyAsync on PState are implemented at the path level. Only built-in navigators support fine-grained reactivity – the codepaths needed to implement that for custom navigators aren’t currently exposed. You can use a custom navigator in a proxy call, but the diff you get from that point in the path will be a coarse-grained NewValueDiff. See the page on PStates for more details on reactivity.
Summary
Paths can be intimidating when you first learn them. There are a lot of different navigators, and we certainly did cover a lot of material on this page. The good news is you don’t need to master or even know every navigator to get huge value out of paths. You can go very far with even just the basic value navigators and a couple filter navigators. Once you get more practice using paths such that you internalize their mental model, you’ll find learning new navigators to be a cinch.
As mentioned, not every navigator was covered on this page. Be sure to check out the Javadoc for Path for the complete listing.