Distributed programming in Rama
Now that you have a basic understanding of how to do work in Rama, let’s explore Rama’s model for distributing that work. This page will teach you:
-
Rama’s distributed programming model
-
The mechanics of working with that model
-
The model’s implications for you, the developer, as you design your application
Distributed programming is the practice of coordinating work and resources so that work can be performed by distributed systems — networked machines which communicate by message passing. It’s a deep topic, and this tutorial isn’t meant to get you to a point of deep expertise with it.
Indeed – part of the point of Rama is that you don’t need deep expertise to be productive. Instead, we’ll cover enough theory and concepts so that you’ll be able to reason about what’s going on in your cluster, and we’ll spend most of the time focusing on how to use Rama’s tools and abstractions to build working applications.
Why distributed?
On the conceptual end, let’s start by discussing why you’d want to build a distributed system; this will help us understand the rationale underlying Rama’s design.
There are three main reasons you might want to develop a distributed system:
-
Separation of concerns. You simply need to communicate with other systems that have their own, separate purpose. Indeed, much of modern development involves working with distributed systems in some fashion in that at the very least you’re dealing with client/server interactions with a database.
-
Performance. You want your application to handle more load, and to do that it needs to be deployed to more machines. Your application should be able to scale to more load in the future by adding machines.
-
Resilience. You want your application to be resilient to failure, allowing it to stay up longer. This usually involves creating clusters where a leader replicates its state to followers that can take over if the leader fails for some reason.
While Rama’s design addresses each of these needs, right now we’re only going to focus on the aspects of the design that support performance. Specifically, we’re going to look at how Rama’s design makes it trivial to distribute work across multiple machines, and we’re going to look at the constructs that Rama provides to leverage this capability.
Designed for performance: the task model
In a Rama module you define all the storage and implement all the logic needed for your backend. Modules can have any number of depots, topologies, and PStates. When you deploy a module to a Rama cluster, you specify how much parallelism it should have, which consists of three main parameters:
-
Tasks
-
Threads
-
Workers
A "task" is a partition of a module. A module with four tasks could look like this:
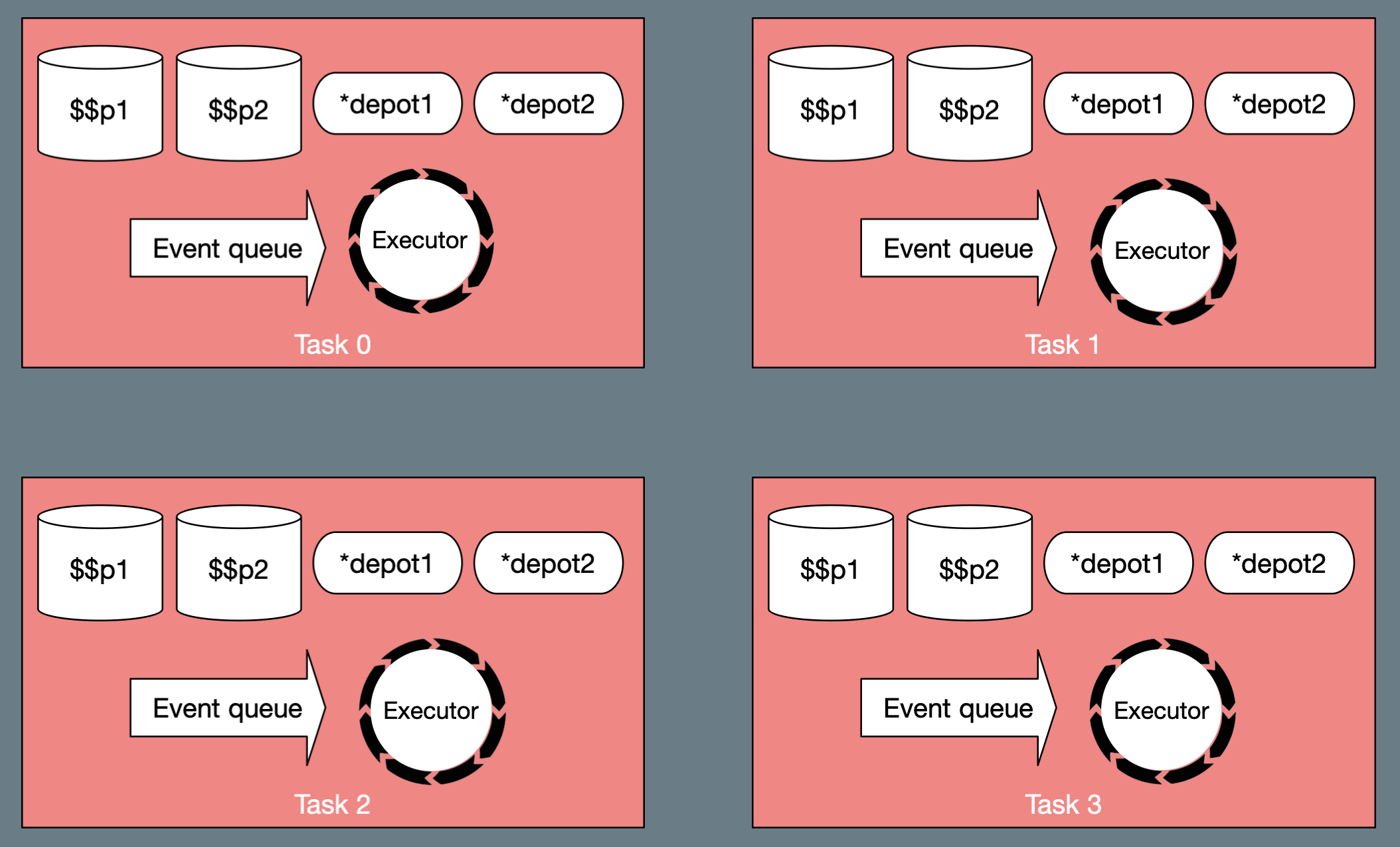
A task contains one partition of every depot and PState for the module as well as an event queue for running events on that task. A running event has access to all depot and PState partitions on that task. Coding a topology involves reading and writing to PStates, running business logic, and switching between tasks as necessary. The number of tasks must be a power of two.
Tasks are like green threads. You specify the mapping of tasks to actual threads and processes with the "threads" and "workers" parameters. If you specify a module should have 64 tasks, 32 threads, and 8 workers, then each thread will run two tasks. 8 JVM processes called "workers" will be spawned around the cluster each with 4 threads. You scale a module up or down by changing the number of threads and workers.
Rama’s dataflow API, which you’ve gotten a small taste of so far, makes it seamless to jump around the cluster between tasks to query and manipulate different partitions of different PStates.
|
The term "task" is overloaded in the world of programming. In talking about a Rama program, you might say something like "That module has eight tasks", meaning there are eight copies of the module concurrently running; or you might say "there are eight tasks running this module" to mean essentially the same thing. Tasks are identified by index, starting with zero; if you launch a module with eight tasks you would refer to tasks zero through seven and say things like "It seems like task zero is seeing significantly more load". |
Here’s a recap of how modules work:
-
When you define a module, you define the module’s depots, ETLs, and PStates.
-
To run a module, you launch it on a cluster.
-
At runtime, records are appended to depots.
-
ETLs read depot records and perform a sequence of actions for each record.
-
That sequence of actions includes updating PStates.
-
Queries read and transform PState data.
Up to this point this description of modules has been presented as if a module runs on only a single task — as if depot and PState data is stored in a single place and ETLs are executed on a single thread. Let’s consider what it means for a module to run on two tasks.
PStates and depots are partitioned across tasks
First, as mentioned PStates and depots are partitioned across tasks. To partition a data store is to map a logical entity to multiple, separate physical locations, called partitions.
For example, consider a module launched with two tasks that has a
"$$wordCounts" PState. At the logical level, you think about the
"$$wordCounts" PState in terms of its schema and its purpose within its
module (storing word counts). At the physical level, the PState is divided into
two partitions, one per task, and when a task executes an ETL it uses the
identifier "$$wordCounts" to refer to the partition for "$$wordCounts"
which belongs to that task.
This has huge implications: If you launch a module and an ETL on task 0
increments the count for the word "ostentation", and an ETL on task 1 does the
same, then each of the partitions for "$$wordCounts" will contain the entry
{"ostentation": 1}, even though the word has been counted two times globally.
It’s very unlikely you want this result. Instead, you want the word
"ostentation" to always be handled by the same task because you want its
associated count to only be recorded and updated on a single partition. You want
to be able to control where data is sent and where work is performed. Rama has
tools to let you do this easily, which we’ll look at next.
Partitioning, the verb
You control where work is performed with partitioners. There are two places you can use partitioners:
-
In a depot’s definition
-
In ETLs
A depot partitioner defines which task Rama clients send a record to when they append a record to a depot. ETL partitioners let you relocate an ETL to a different task.
To get a better sense of what this all means, let’s revisit the simple word count example to see how partitioners are declared and used:
package rama.examples.tutorial;
import com.rpl.rama.*;
import com.rpl.rama.module.*;
import com.rpl.rama.test.*;
public class SimpleWordCountModule implements RamaModule {
@Override
public void define(Setup setup, Topologies topologies) {
setup.declareDepot("*wordDepot", Depot.random());
StreamTopology s = topologies.stream("wordCountStream");
s.pstate("$$wordCounts", PState.mapSchema(String.class, Long.class));
s.source("*wordDepot").out("*token")
.hashPartition("*token")
.compoundAgg("$$wordCounts", CompoundAgg.map("*token", Agg.count()));
}
}This module defines a depot with setup.declareDepot("*wordDepot",
Depot.random());. The first argument, "*wordDepot", is the
depot’s identifier. The second argument, Depot.random(), is the depot’s
partitioner.
In this case, we’re saying we want to use a random partitioner, meaning that
when a Rama client appends a record to this depot, the record will be sent to a
random task and added to that task’s "*wordDepot" partition.
|
Random partitioning isn’t the best method to use here because it’s inefficient; after we’ve covered the mechanics of how partitioners work, we’ll explore how to make good decisions around partitioning and consider the design implications that first-class partitioning has for your application. |
So that’s how depot partitioners work. An example of an ETL partitioner is
.hashPartition("*token"). .hashPartition is the partitioner,
and its purpose is to relocate the rest of the ETL to a different task. To
relocate an ETL is to transfer the current scope — the bindings created by
.out — to a task, and restore the scope on that task and resume the ETL from
where it left off. In conversation, we also say that the ETL partitions to a
task to mean that the ETL has relocated.
Let’s walk through a timeline to better understand how this works:
-
depot.append("one")appends the string"one"to a random depot partition. Let’s assume that this is the depot’s partition 0, ord0for short. -
Task 0, which owns
d0, is running the ETLs. Also,d0is referred to as"*depot"within task 0. The first step ofsiss.source("*depot").out("*token"), which reads records from"*depot"and binds them to"*token". -
The next step of ETL
sis.hashPartition("*token"). It determines which PState partition the input "belongs" to, then it partitions to the corresponding task. In this case, we have two tasks so the ETL will partition to either task 0 or task 1, transferring its scope. Let’s assume it partitions to task 1. -
The ETL resumes where it left off: the step
.compoundAgg("$$wordCounts", CompoundAgg.map("*token", Agg.count()))updates the$$wordCountspartition for task 1, increasing the count that corresponds to the string"one".

As the application continues to run, it’s possible for the string "one" to get
appended to "*depot" more times. It will continue getting randomly appended to
either the depot partition on task 0 or on task 1, but the ETL will always
result in the $$wordCounts partition on task 1 getting updated because
hashPartition("*token") will always partition to task 1 when
"*token" is bound to the string "one".
To recap:
-
Rama modules run on one or more concurrently executing tasks.
-
Tasks are identical in structure and function, but differ in the contents of their depot and PState partitions.
-
Depot partitioners determine which depot a record gets appended to.
-
ETL partitioners relocate an ETL run to another task.
-
It’s up to you to design your partitioners so that data and work get routed to the right task.
This last point is unique to Rama, and has larger implications for how you design your application.
Designing applications for tasks
Rama brings partitioning to the fore when you’re writing your application. It is a first-class resource management concern that is your responsibility to handle correctly. Rama helps you out by giving you a simple model and simple tools so you only have to worry about the inherent complexity of partitioning, not the incidental complexity that systems can introduce.
In dealing with the inherent complexity of partitioning, there are two main considerations to keep in mind:
-
Performance
-
Consistency
Let’s explore each of these.
Performance
We touched on performance above when we mentioned that the random partitioner of "*wordDepot" introduces an inefficiency: it sometimes routes an append to a task other than the one containing the partition where we’ll store the word’s count. This requires an extra network hop to transfer the word to the correct partition.
You could rewrite the module as follows to avoid this inefficiency:
package rama.examples.tutorial;
import com.rpl.rama.*;
import com.rpl.rama.module.*;
import com.rpl.rama.test.*;
public class SimpleWordCountModule implements RamaModule {
@Override
public void define(Setup setup, Topologies topologies) {
setup.declareDepot("*wordDepot", Depot.hashBy(Ops.IDENTITY); (1)
StreamTopology s = topologies.stream("wordCountStream");
s.pstate("$$wordCounts", PState.mapSchema(Object.class, Object.class));
s.source("*wordDepot").out("*token")
(2)
.compoundAgg("$$wordCounts", CompoundAgg.map("*token", Agg.count()));
}
}| 1 | This changes the depot’s partitioner from Depot.random(), which produces a
random hash value, to Depot.hashBy(Ops.IDENTITY), which produces a hash
based on the appended record’s value. |
| 2 | We can remove the call to .hashPartition("*token") because
the words are already being sent to the right partition deterministically. |
This is just a very small example of how your partitioning scheme has a direct impact on your application’s performance. As you work with Rama, you’ll get a better feel for designing with where in mind.
This design consideration becomes even more important in realistic applications, where you have to decide where to store multiple related pieces of information. The more you can store related information on the same partition, the less time it will take to retrieve it all – you won’t have to jump around to separate tasks, possibly incurring extra network hops, to collect or update the information you need.
Consistency
A less obvious implication of Rama’s distributed design is that the where element has implications for your data’s consistency. Consider the following scenario:
-
You have a module that includes user profiles.
-
User profile edits are appended to a depot.
-
That depot has a random partitioner.
-
An ETL reads these edits and partitions on username.
Now consider this timeline for the user bananaman. Assume that the ETL
processing profile edits partitions the username bananaman to task 1.
-
bananamansubmits an edit and it arrives atdepot-0, the depot partition on task 0 -
bananamansubmits an edit and it arrives atdepot-1, the depot partition on task 1 -
etl-0, the ETL starting on task 0, reads the edit fromdepot-0. -
etl-1, the ETL starting on task 1, reads the edit fromdepot-1. -
etl-0partitions to task 1. -
etl-1processes its edit and stores it in a PState. -
etl-0arrives on task 1. -
etl-0processes its edit and stores it in a PState, incorrectly replacing the data from the second edit with the data from the (stale) first edit.
Rama has no guarantees about the global order in which depot records are processed, so this hypothetical module design introduced the possibility for race conditions.
The way to solve this is to introduce a depot partitioner. Rama does guarantee that all local depot partition records are processed in the order in which they’re received (indeed, messages sent between any two points are processed in the order that they’re received). This would guarantee that the second edit would be processed after the first, and that the fresh data would always overwrite the stale data.
Summary
Distributed programming is the practice of coordinating work and resources so that work can be performed by distributed systems — networked machines which communicate by message passing. Some systems are naturally distributed by their architecture or separation of concerns; client/server systems, for example. For other systems, we employ a distributed architecture for better performance and resiliency.
Rama is distributed to provide better performance and enable resiliency. In this chapter, we focused on the performance aspect: Rama systems improve performance by spreading work across multiple nodes.
The underlying design abstraction that enables this is the task model. Tasks are similar to processes in that they’re the runtime manifestation of module. ETL execution takes place within a task, and tasks expose storage resources (depots and PStates).
Depots and PStates are partitioned across tasks, meaning that each such
logical entity is split into separate physical storage locations, one per
task. When you refer to a PState or depot (for example, the PState
$$wordCount) from within an ETL, you are referring to that entity’s partition
for the current task.
Within an ETL you can partition in the verb sense, meaning that the current
execution of the ETL gets relocated to a different task. When you relocate an
ETL, its scope travels with it. Anything you’ve bound with .out() will
continue to be available, while PState and depot references will point to the
current partitions.