Dataflow language
ETL and query topologies are defined using Rama’s dataflow API. This API is a full Turing-complete language of its own, just like Clojure, with the ability to seamlessly express arbitrary distributed computation. This page will explore all aspects of this language.
Examples on this page can be run from the rama-clojure-starter project with lein repl. You should require the following namespaces to run the examples:
(use 'com.rpl.rama)
(use 'com.rpl.rama.path)
(require '[com.rpl.rama.ops :as ops])
(require '[com.rpl.rama.aggs :as aggs])Basic structure of dataflow code
Clojure and most other languages are based on the "call and response" paradigm. You call a function with some number of arguments, and it returns a single result back. Rama is based on "call and emit", which is a generalization of "call and response".
With "call and emit", you call an operation with some number of arguments and it emits values to downstream code. It can emit one value, many values, or even zero values. Additionally, it can emit to multiple independent "output streams". "Call and response" is "call and emit" with the restrictions of one output stream, exactly one emit to that output stream, exactly one field in that emit, and that emit being the last thing done by the operation.
Let’s start with an example of code emitting to a single output stream:
(deframaop foo [*arg]
(:> (inc *arg))
(:> (dec *arg)))
(?<-
(foo 5 :> *v)
(println "Emitted:" *v))foo takes in one argument that’s bound to the variable *arg. It then emits two times using :> as an operator. Rama operations can emit to any number of output streams any number of times. :> is the default output stream, and you can specify named output streams with operations like :another-stream> or :a-different-stream>. A caller of an operation captures values to output streams by using output stream keywords in their invoke. In this case, the caller of foo captures values into the default output stream and binds emits to the variable *v. This prints:
Emitted: 6
Emitted: 4deframaop defines a custom operation using the dataflow API. ?<- compiles and executes a block of dataflow code. This code calls the custom operation foo, binds emitted values to the variable *v, and prints the results.
Dataflow code consists of a sequence of "segments", analogous to a "form" in Clojure (since Rama dataflow is still Clojure, segments are also technically forms). A segment consists of an operation, input fields, and any number of "output declarations". An "output declaration" begins with an "output stream" followed by an optional "anchor" and any number of "variables" to bind for emits to that stream. Here are some examples of segments:
(+ 1 2 3 :> *sum)
(bar :a> <aaa> *v1 *v2
:b> <anchor-b> *v2
:> *a)
(println "Hello")An "output stream" is a keyword ending with >. These examples have output streams :>, :a>, and :b>.
An "anchor" labels a point in dataflow code with a unique ID. An anchor is a symbol wrapped in < and >. It has no effect at runtime and is just used to implement branching and merging in dataflow.
A "variable" is a symbol beginning with *, %, or $$. * signifies a value, % signifies an anonymous operation, and $$ signifies a PState. This naming structure allows Rama to distinguish between dataflow variables and regular Clojure symbols that refer to constants that should be inserted into dataflow code. For example, you can do this:
(def some-constant 10)
(?<-
(+ some-constant 3 :> *res)
(println "Res:" *res))This prints:
Res: 13You can also nest expressions in dataflow code just like you can with Clojure. For example:
(?<-
(* (- 10 4) (+ 1 (+ 2 3)) :> *res)
(println "Res:" *res))This prints:
Res: 36Nested expressions like this implicitly capture a single value emitted to :> and use that value at that position. The return of a regular Clojure function is implicitly translated to an emit to :>. :> is called the "default output stream".
Clojure macros get expanded first during Rama compilation, so you can write code like this:
(?<-
(println "Res:" (-> 10 (+ 3) (* 4))))This prints:
Res: 52Continuation-passing style
The "call and emit" paradigm is related to "continuation-passing style". This blog post explores this in detail by showing how Rama dataflow code works by comparing against equivalent Clojure code written in continuation-passing style.
Branching
Let’s take a look at more complicated dataflow code with branching:
(deframaop foo [*arg]
(:> (inc *arg))
(:> (* 10 *arg))
(:other> (dec *arg)))
(?<-
(foo 5 :other> <other> *v :> *v)
(anchor> <default-root>)
(println "Default output stream 1:" *v)
(hook> <default-root>)
(println "Default output stream 2:" *v)
(hook> <other>)
(println "Other output stream:" *v))Here’s a visualization of the code in the ?<- block:
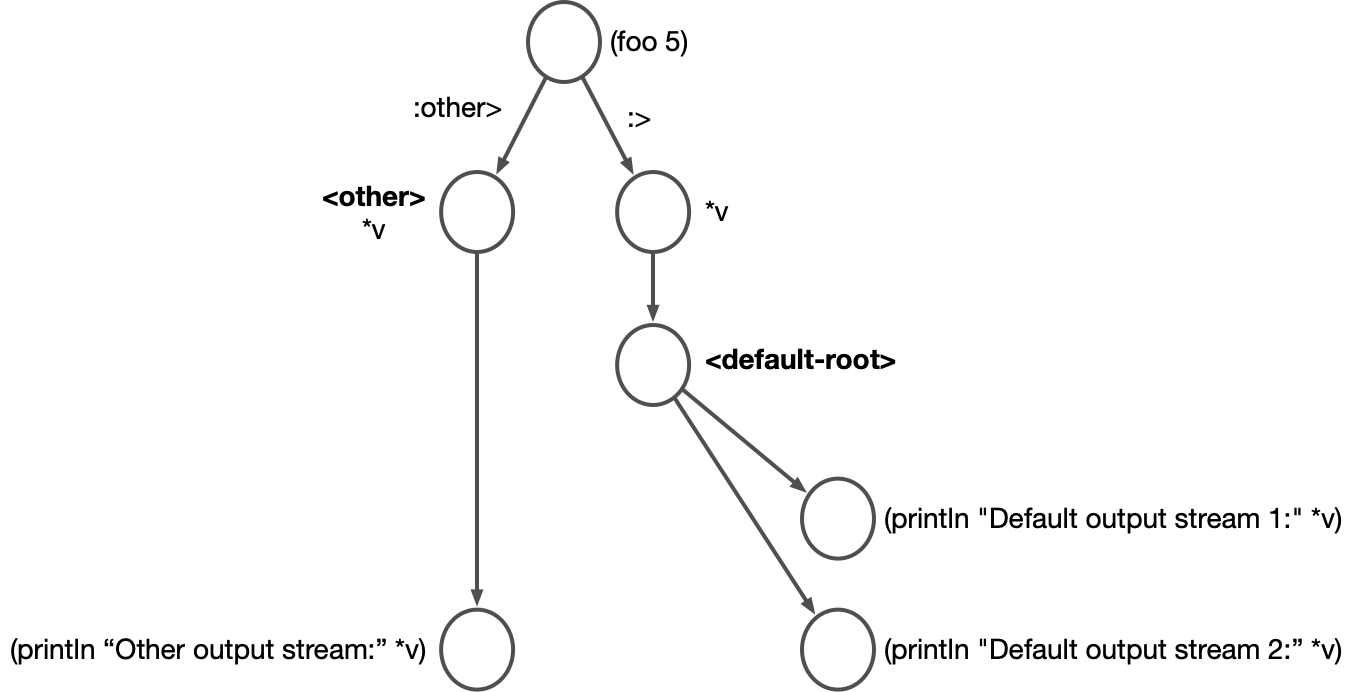
hook> and anchor> in this code are used to create a branching dataflow graph. Usually when you write a new segment, it attaches to the most recent node created in the dataflow graph. hook>, however, changes the attach point of the subsequent segment. anchor> creates a no-op node with the specified anchor.
The order of emits for the foo callsite is determined by the order in which foo emits to those streams. So the code attached to :> will run twice, and then the code attached to :other> will run once. There is nothing controlling the ordering on the two branches attached to <default-root>, however. This is called an "unordered branching", and the order in which the branches are run is nondeterministic. Unordered branchings are common in ETL code for multiple independent branches of processing that are not related to each other.
So when this code is run, there are two possible outputs. The first possible output is:
Default output stream 1: 6
Default output stream 2: 6
Default output stream 1: 50
Default output stream 2: 50
Other output stream: 4The other possible output is:
Default output stream 2: 6
Default output stream 1: 6
Default output stream 2: 50
Default output stream 1: 50
Other output stream: 4Unification
You can merge dataflow branches together with "unification", specified with unify>. Here’s a basic example:
(deframaop multi-out []
(:a> 1)
(:b> 2))
(?<-
(multi-out :a> <a> *v :b> <b> *v)
(unify> <a> <b>)
(println "Val:" *v))This prints:
Val: 1
Val: 2All emits flowing through unify> flow into its continuation as if the continuation to unify> were attached independently to each of the anchors specified. You can unify as many anchors as you want with unify>.
Rama has rigorous rules on variable scope and how variable scope works with unification. A variable is considered in scope after a unify only if it is bound on all branches leading to the unify>. For example, this code will fail to compile because *v is defined on only one of the branches:
(deframaop multi-out []
(:a> 1)
(:b> 2))
(?<-
(multi-out :a> <a> *v :b> <b> *v2)
(unify> <a> <b>)
(println "Val:" *v))It’s impossible for the continuation to unify> to run in this case for emits to :b> since *v doesn’t exist along that path.
The same rules apply for shadowing. Consider this code:
(?<-
(identity :orig :> *v)
(identity :new :> <a> *v :b> <b> *v2)
(unify> <a> <b>)
(println "Val 1:" *v)
(identity :new2 :> <a2> *v :b> <b2> *v)
(unify> <a2> <b2>)
(println "Val 2:" *v))This prints:
Val 1: :orig
Val 2: :new2In the first unify, *v is shadowed only on the :> branch. Because it is not shadowed on all branches, the version of *v that’s in scope after the first unify> is the original binding of :orig. In the second unify>, on the other hand, *v is shadowed in all branches. So the value of *v in this case is the shadowed version :new2. This behavior keeps unify> consistent between binding new variables and shadowing existing variables.
More generally than this, Rama is strict about variable scope and will throw compilation errors if you ever reference a variable that’s out of scope.
Finally, with unify> you can see that Rama dataflow code is a graph of computation. So whereas code for traditional languages creates what’s called an "abstract syntax tree" (AST), Rama code creates an "abstract syntax graph" (ASG). This data structure is explicitly reified internally as part of Rama compilation.
Destructuring
You can destructure data structures in Rama code just like you can in Clojure. Here are a few examples:
(?<-
(identity {:a 1 :b 2} :> {:keys [*a *b] :as *m})
(println "Destructure 1:" *a *b *m)
(identity {:k [7 8 9]} :> {[*a *b *c] :k})
(println "Destructure 2:" *a *b *c))This prints:
Destructure 1: 1 2 {:b 2, :a 1}
Destructure 2: 7 8 9Rama uses the name of the variable without the leading * to determine what keyword to look up in the destructured data structure.
Conditionals
Rama has a few ways to specify conditional logic. The most common one is <<if. Here are a few examples:
(?<-
(<<if (= 1 2)
(println "True")
(else>)
(println "False"))
(<<if (= 1 1)
(println "A"))
(<<if false
(println "B")))This prints:
False
AJust like Clojure’s if, <<if executes either a "then" branch or an optional "else" branch based on the truthiness of the provided value. (else>) is used to separate a block of "then" code from a block of "else" code. The "then" and "else" branches are automatically unified together, regardless of whether an "else" block is specified.
<<if is built upon the primitive operation if>. if> works just like any other Rama operation by having :then> and :else> output streams. For example:
(?<-
(if> (= 1 1) :else> <e> :then>)
(println "True branch")
(hook> <e>)
(println "False branch"))This prints:
True branchUnlike Clojure and other programming languages, if> is not a special form. It can be passed around as an anonymous operation just like anything else. However, when it’s used statically like in this example the Rama compiler recognizes that and generates optimized bytecode for the callsite that’s equivalent to what Clojure generates for if.
Another operation for performing conditional logic is ifexpr, which works just like Clojure’s if. It’s meant to be used as a nested expression which "returns" a value, like so:
(?<-
(println "Res 1:" (ifexpr true (* 1 1) 2))
(println "Res 2:" (ifexpr false 10)))This prints:
Res 1: 1
Res 2: nilFinally, Rama has an analogue to cond called <<cond. Here’s an example:
(?<-
(<<cond
(case> (= 1 2))
(println "A")
(identity 1 :> *v)
(case> (> 2 1))
(println "B")
(identity 2 :> *v)
(case> (= 1 1))
(println "C")
(identity 3 :> *v))
(println "Val:" *v))This prints:
B
Val: 2Just like <<if, all branches of <<cond are automatically unified together. So variables defined along all branches will be in scope after the <<cond block. This also means that if none of the cases match, the code after <<cond will not execute. For example:
(?<-
(<<cond
(case> (= 1 2))
(identity 1 :> *v)
(case> (= 1 3))
(identity 2 :> *v))
(println "Val:" *v))This doesn’t print anything.
Likewise, as is the same for all dataflow code, the continuation to a <<cond callsite can execute multiple times if the code within a branch emits multiple times. For example:
(deframaop foo []
(:>)
(:>))
(?<-
(<<cond
(case> (= 1 2))
(identity 1 :> *v)
(case> true)
(identity 2 :> *v)
(foo))
(println "Val:" *v))This prints:
Val: 2
Val: 2<<cond also accepts a "default" branch that runs if none of the other branches match. Here’s an example:
(?<-
(<<cond
(case> (= 1 2))
(identity 1 :> *v)
(case> false)
(identity 2 :> *v)
(default>)
(identity 3 :> *v))
(println "Val:" *v))This prints:
Val: 3Sometimes you don’t want any implicit unification on the default> branch. A common scenario for this is when the default branch is meant to throw an exception but you still want common variables in the other branches to be in scope after the <<cond. You can do this like so:
(?<-
(<<cond
(case> (= 1 2))
(identity 1 :> *v)
(case> (= 1 1))
(identity 2 :> *v)
(default> :unify false)
(throw! (ex-info "Exception" {})))
(println "Val:" *v))This prints:
Val: 2Without the :unify false, this code would throw a compilation exception about *v not being in scope.
Loops
Rama has a looping construct called loop<- that’s similar to Clojure’s loop, except with dataflow semantics. Whereas Clojure’s loop returns the terminal value of the loop, Rama’s loop<- emits values explicitly can can emit multiple times and multiple fields per emit. Here’s a basic example:
(?<-
(loop<- [*i 0 :> *v]
(println "Loop iter:" *i)
(:> *i)
(<<if (< *i 3)
(continue> (inc *i))))
(println "Emit" *v))This prints:
Loop iter: 0
Emit 0
Loop iter: 1
Emit 1
Loop iter: 2
Emit 2
Loop iter: 3
Emit 3The order of the prints here indicates how execution works: when emitting from the loop with :>, the continuation of the loop is invoked immediately. This is the same behavior as when an operation emits. The continue> call happens after the continuation of the loop finishes executing.
loop<- receives a binding vector of zero or more vars, with each var given an initial value. Unlike the bindings for a Clojure loop, the binding vector also includes bindings for the output variables of the loop. Just like Rama operations, a loop can emit zero or more fields per emit. Here’s an example of a loop with multiple binding variables and emitting multiple fields:
(?<-
(loop<- [*i 1
*j 1
:> *v1 *v2]
(<<if (= *i 5)
(:> *i *j)
(else>)
(continue> (inc *i) (* *j *i))))
(println "Emit" *v1 *v2))This prints:
Emit 5 24continue> executes another iteration of the loop. Unlike Clojure’s recur, you can actually continue> multiple times per iteration of a loop under certain conditions. Specifically, if the body of the loop goes async (like with a partitioner), the body can call continue> multiple times in one iteration. An example use case where this comes up is a query topology doing a parallel graph search, where each iteration of the loop continues along all outgoing edges.
Inline hooks
Rama has a small convenience feature called "inline hooks" when you want to attach a single segment to an output stream without needing to deal with hooks/anchors explicitly. The syntax for this is :>> and looks like this:
(deframaop foo []
(:a> 1)
(:>))
(?<-
(foo :a> *v :>> (println ":a>" *v)
:>)
(println "Normal output"))This prints:
:a> 1
Normal outputThis code is equivalent to:
(deframaop foo []
(:a> 1)
(:>))
(?<-
(foo :a> <a> *v
:>)
(println "Normal output")
(hook> <a>)
(println ":a>" *v))An inline hook is inserted after the variables for an output declaration and can consist of only a single segment.
Custom operations
There are a variety of ways to decompose dataflow logic into separate operations. Some of these ways involve writing regular Clojure code, and other ways involve writing operations with Rama’s dataflow API.
The first way to decompose logic is with plain Clojure functions. You can always call a Clojure function from dataflow code, as the "call and response" paradigm of Clojure functions is a subset of the "call and emit" paradigm of Rama. When you call a Clojure function, it’s return value is implicitly emitted as a single field to the :> stream. For example:
(?<-
(+ 1 2 3 :> *v)
(* *v 10 :> *v2)
(println *v2))This prints:
60"Fragment" is the term for objects that can be invoked and emit an arbitrary amount to arbitrary output streams. These are broken down into two categories: "ramafn", which are fragments that emit to :> exactly one time and perform no more work afterwards (like a Clojure function), and "ramaop", which has no restrictions on emits.
defoperation is a way to define a "ramaop" in Clojure. Here’s an example:
(defoperation foo-op
[out> :>
a> :a>]
[arg1 arg2]
(doseq [i (range arg2)]
(a> i (str i "!")))
(out> (str arg1 "?")))
(?<-
(foo-op "abc" 3
:a> *i *v :>> (println ":a>" *i *v)
:> *v)
(println ":>" *v))This prints:
:a> 0 0!
:a> 1 1!
:a> 2 2!
:> abc?The first binding vector binds symbols to output streams, in this case out> to the :> stream and a> to the :a> stream. The next binding vector is the arguments to the defoperation. Note that defoperation does a code transformation internally to connect the out> and a> symbols to the appropriate output streams, so those symbols aren’t functions that can be passed to other functions. When out> and a> are "called", the arguments are emitted to the corresponding output streams.
The next way to define a ramaop is with deframaop. This defines the ramaop with dataflow code. Here’s an example:
(deframaop foo [*list]
(ops/explode *list :> *v)
(<<if (= *v :a)
(:a>)
(else>)
(:> *v)))
(?<-
(foo [1 2 :a 3 4]
:a> :>> (println ":a>")
:> *v)
(println ":>" *v))This prints:
:> 1
:> 2
:a>
:> 3
:> 4Emits from a deframaop are done by using the output stream as an operation. Internally, these callsites become interface invokes at the bytecode level.
You can define a ramafn with dataflow code with deframafn. The definition is exactly the same as deframaop, but the body must emit to :> exactly once, and that must be the last thing the deframafn definition does. A deframafn can emit to other output streams arbitrarily. Here’s an example:
(deframafn foo [*v1 *v2]
(:a> (+ *v1 *v2))
(:a> (- *v1 *v2))
(:> (* *v1 *v2)))
(?<-
(foo 5 3
:a> *v :>> (println ":a>")
:> *v)
(println ":>" *v))This prints:
:a>
:a>
:> 15If a deframafn emits to :> zero times or more than once, there will be a runtime error. A deframafn can also be called directly from Clojure, though the only output Clojure can capture is the value emitted to :>. For example, the previous deframafn can be called like this:
(println (foo 5 3))This prints:
15Anonymous operations can be defined in dataflow code with <<ramaop and <<ramafn. These have the same syntax as deframaop and deframafn, and just like Clojure functions they capture their lexical closures. Here’s an example:
(?<-
(identity 10 :> *v)
(<<ramafn %f [*a]
(:> (+ *a *v)))
(println "Res:" (%f 1) (%f 2)))This prints:
Res: 11 12A variable beginning with % signifies an anonymous operation, whether ramafn or ramaop. They can be passed around just like Clojure functions. For example:
(deframafn foo [%f]
(:> (%f 10)))
(?<-
(<<ramafn %f [*a]
(:> (* *a 5)))
(println "Res:" (foo %f)))This prints:
Res: 50In this code, the compilation of foo doesn’t know whether %f is a ramaop or ramafn so it generates bytecode that works for either case. If you know for sure that an anonymous operation is a ramafn, you can hint it with ramafn> to enable the Rama compiler to generate more efficient bytecode. foo in the previous example can be written more efficiently like so:
(deframafn foo [%f]
(ramafn> %f)
(:> (%f 10)))Note that <<ramaop and <<ramafn end up with randomized class names, so they should not ever be written into PStates or depots. Otherwise, they won’t be able to be deserialized after a module update when the underlying classes can potentially change.
Lastly, when a Clojure function gets used as a constant, it gets wrapped as a ramafn so it can be invoked like an anonymous operation. For example:
(deframafn foo [%f]
(ramafn> %f)
(:> (%f 10)))
(?<-
(println "Res:" (foo inc)))This prints:
Res: 11Special :clj> output stream
When using ?<-, you can return a value back to the caller of the ?<- using the special :clj> output stream. For example:
(?<-
(+ 1 2 :> *v)
(:clj> (* 10 *v)))This expression will return the value 30.
Since ?<- compiles its body each time it’s called, it shouldn’t be used for production code that needs to interoperate between Clojure and Rama. Its use should be limited to experimentation and unit tests.
The way to return values from Rama to Clojure in production would be to define a ramafn and call it from Clojure.
Differences between Clojure and Rama’s dataflow API
Here’s a list of important differences between Clojure and Rama’s dataflow API:
-
You can’t do Java interop in Rama code (e.g.
(.size l)). Instead, you should make a wrapper function in Clojure and call that wrapper function from Rama. -
You can’t use Clojure’s
fnin Rama code since it’s a special form. Instead, use<<ramaopor<<ramafnas described in the previous section. -
Rama dataflow has no support for primitives.
-
None of Clojure’s special forms will work in Rama dataflow. Macros that expand to special forms, like
andandorwhich expand toif, also cannot be used. Rama has alternatives forandandorcalled and> and or> that have the exact same short-circuiting semantics. -
Clojure inserts var indirection for all non-local symbol references. Rama only inserts var indirection for functions/operations in the operation position of a segment. Notably, symbol references used as fields do not have var indirection and get inserted as constants in the code instead. This impacts how with-redefs works with Rama code.
-
Because Rama doesn’t use var indirection for constants, values in Rama code used as constants must be able to be "serialized" into bytecode. Currently this is only supported for basic types (e.g. strings, numbers), records, Clojure data structures, functions, and implementations of RamaSerializable. Notably, mutable objects like volatiles are not allowed. When using
?<-, Rama will support arbitrary constants with an "object cache" so that the compiled bytecode can reference those unsupported constants. However, the object cache cannot be used for modules as it requires shared memory. So trying to use something like a volatile in module code will lead to an "object cache not allowed" error.
Partitioners
Partitioners are operations that potentially emit on a different task on a different machine. Some partitioners can emit multiple times across multiple tasks in parallel. Just like other fragments, partitioners are an instance of the "call and emit" paradigm. Unlike the other fragments you’ve seen so far, partitioners emit asynchronously. However, code using partitioners is still read linearly, and partitioners compose arbitrarily with any other dataflow code like conditionals and loops.
Here’s an example of using a few partitioners in dataflow code:
(identity 3 :> *v)
(|hash *k)
(local-transform> [(keypath *k) (termval *v)] $$p)
(|all)
(local-transform> (term inc) $$counter)The naming convention for partitioners is to prefix them with |. The task before and after a partitioner may be different, and Rama takes care of all the networking and serialization necessary to move the computation. In this case, |hash chooses the target task according to the hash of the provided value. So the same key will always go to the same task, and different keys will be evenly distributed across all tasks. |hash moves from one task to exactly one other task. |all, on the other hand, moves the computation to all tasks (including the current one). So if the module has 64 tasks, |all emits 64 times.
Internally, Rama does variable scope analysis to determine what needs to be serialized/transferred across a partitioner boundary. In this case, *v is transferred across the |hash because it’s used afterward, but it is not transferred across |all since the code after makes no reference to it.
For a complete explanation of how partitioners function, see this page.
Most of the partitioners have a $$ variant, such as |hash$$. These variants take in a depot or PState as the first argument and partition based on the number of partitions of that object. For depots and PStates belonging to the same module, who have the same number of partitions as tasks of the module (unless declared as "global"), there’s no difference. The $$ variants are usually used with mirror depots or PStates.
For a complete listing of built-in partitioners available, consult the API docs.
You can also write custom partitioners using |custom and |custom$$. These are passed a function that chooses the target partition. For example:
(<<ramafn %custom
[*num-partitions *arg1 *arg2]
(:> (mod (+ *arg1 *arg2) *num-partitions)))
(|custom %custom 10 -11)The first argument is the number of partitions, and the additional arguments are whatever is passed to |custom. The return value must be between 0 and the number of partitions.
Aggregators
Aggregators are a way to update PStates, and they can also be used on their own in batch blocks or query topologies. In some cases they let you specify transformations in a little less code, and in other cases they enable huge increases in performance and expressivity. See the main page on aggregators for a general discussion of the concepts of aggregators and different scenarios where they can be used.
In the Clojure API aggregators are used like any other operation. The com.rpl.rama.aggs namespace contains many built-in aggregators. Here’s an example of using an aggregator to update a PState containing a top-level number in each partition:
(aggs/+sum $$p *v)This adds *v to the number already in $$p. With local-transform> this would be expressed as:
(<<ramafn %adder [*n]
(:> (+ *n *v)))
(local-transform> (term %adder) $$p)The naming convention of aggregators is to prefix them with +. This isn’t necessary, but we find this helps with readability.
+compound enables aggregation of nested values, expressing a transform in the shape of the structure being written. For example, here’s how to add numbers to values in a map:
(+compound $$p {*k (aggs/+sum *v)})This is equivalent to:
(<<ramafn %adder [*n]
(:> (+ *n *v)))
(local-transform> [(keypath *k) (nil->val 0) (term %adder)] $$p)Aggregators understand the concept of a "zero val", so they automatically take care of initializing a value when writing to a non-existent location for the first time.
+compound can also do multiple aggregations at the same time, like so:
(+compound $$p {*k {:a [(aggs/+sum *v) (aggs/+count)]
:b (aggs/+max *v2)})In a batch block in a microbatch topology, +compound also supports capturing newly updated values and the keys leading up to those updated locations. One context where this is invaluable is "top N" analytics, and the feature is described fully in this section.
In the Clojure API, this is done with the special :new-val> stream, like so:
(+compound $$p {*k {:a (aggs/+sum *v :new-val> *new-sum)})The postagg phase of the batch block containing this +compound call will explode every updated *k along with its updated *new-sum value.
Another helpful facility for doing aggregation is +group-by. This isn’t used for updating existing PStates, but is often useful as part of a larger batched computation. Here’s an example of using +group-by to get counts and sums grouped by a key:
(?<-
(<<batch
(ops/explode [[:a 1] [:b 2] [:a 3] [:a 4] [:b 10] [:c 9]] :> [*k *v])
(+group-by *k
(aggs/+count :> *count)
(aggs/+sum *v :> *sum))
(println *k *count *sum)
))This prints:
:a 3 8
:b 2 12
:c 1 9You can define custom aggregators using accumulator or combiner.
accumulator defines an aggregator like a reduce function, by specifying how to merge in one piece of data into a total value. Here’s an example of defining +sum as a custom accumulator:
(def +my-sum
(accumulator
(fn [v] (term (fn [v2] (+ v v2))))
:init-fn (fn [] 0)
))The function provided to accumulator returns a path that performs the update. The function can be of any arity, and the arguments passed to the function are the ones passed to +my-sum at the dataflow callsite. :init-fn specifies what to initialize the aggregated value to when first aggregating to a non-existent location.
combiner defines an aggregator by merging two values of the same form into another value of the same form. Unlike accumulator, an aggregation defined with combiner can be executed in parallel. Rama will automatically use two-phase aggregation when all aggregators in a batch block are combiners, and this provides massive speedups in scenarios such as global aggregation.
Here’s an example of defining +sum as a custom combiner:
(def +my-combiner-sum
(combiner + :init-fn (fn [] 0)))In this case the combiner function is just Clojure’s + function, and the :init-fn is just like the accumulator version.
Two built-in aggregators of note are +top-monotonic and +limit. These work a little bit differently than other aggregators and can are extremely useful in certain scenarios.
Batch blocks
"Batch blocks" are another execution mode for dataflow that can be used in microbatch or query topologies. Whereas normal dataflow code executes completely imperatively, batch blocks are partially declarative and have the same capabilities as relational languages like SQL. They support inner joins, outer joins, and subbatches, albeit expressed differently. They also support two-phase aggregation, which among other things enables highly scalable global aggregation.
See this section for an explanation of the semantics of batch blocks and their three phases of operation: pre-agg, agg, and post-agg.
Let’s take a look at some examples of using batch blocks through the Clojure API. Here’s an example of performing a few aggregations:
(?<-
(<<batch
(ops/range> 0 10 :> *v)
(aggs/+sum *v :> *sum)
(aggs/+count :> *count)
(println "Res:" *sum *count)))This prints:
Res: 45 10Here’s an example of an inner join between two datasets:
(?<-
(<<batch
(ops/explode [[:a 1] [:a 2] [:b 2] [:c 3]] :> [*k *v1])
(gen>)
(ops/explode [[:a 10] [:c 4] [:d 100]] :> [*k *v2])
(println "Res:" *k *v1 *v2)))This prints:
Res: :a 1 10
Res: :a 2 10
Res: :c 3 4gen> creates a new root branch in the batch block and is the same as freshBatchSource in the Java API. When the compiler comes to the println segment, it sees that *v1 is not in scope on the current branch. So it searches for a possible join between all branches to bring all needed variables in scope.
Likewise, you can do an outer join using ** variables:
(?<-
(<<batch
(ops/explode [[:a 1] [:a 2] [:b 2] [:c 3]] :> [*k *v1])
(gen>)
(ops/explode [[:a 10] [:c 4] [:d 100]] :> [*k **v2])
(println "Res:" *k *v1 **v2)))This prints:
Res: :a 1 10
Res: :a 2 10
Res: :c 3 4
Res: :b 2 nilHere’s an example of combining a join with aggregation:
(?<-
(<<batch
(ops/explode [[:a 1] [:a 2] [:b 2] [:c 3]] :> [*k *v1])
(gen>)
(ops/explode [[:a 10] [:c 4] [:d 100]] :> [*k *v2])
(+group-by *k
(aggs/+sum *v1 :> *sum1)
(aggs/+sum *v2 :> *sum2))
(println "Res:" *k *sum1 *sum2)))This prints:
Res: :a 3 20
Res: :c 3 4Subbatches allow for multiple rounds of aggregation within one <<batch execution. Here’s an example of a batch block with a subatch:
(defgenerator counts-subbatch [source]
(batch<- [*k *count]
(source :> *k)
(+group-by *k
(aggs/+count :> *count))))
(?<-
(<<batch
(counts-subbatch [:b :a :b :b :c :a] :> *k *count)
(aggs/+limit [2] *k *count :+options {:sort *count :reverse? true})
(println "Res:" *k *count)
))This prints the top two elements in the source vector by frequency:
Res: :b 3
Res: :a 2defgenerator defines a Clojure function that should return a subbatch defined with batch<-. Subbatches have their own pre-agg, agg, and post-agg phases independent of whatever parent subbatch they may be read from. A function marked as a "generator" like this can be used as source in another batch block, and the vector of variables at the start of a call to batch<- indicates what fields that subbatch emits.
You can nest as many generators as you want in the definition of a batch block.
What makes code like this useful versus doing the same thing with sort/frequencies is that the code can execute in a massively scalable way, with the global aggregation of the +limit happening via scalable two-phase aggregation.
Note that <<batch blocks in a module need to specify partitioners. See the main section on batch blocks for details.
In a microbatch topology, you can also materialize the results of a batch block into a temporary PState for reuse later in the microbatch. The operation for this is materialize>. Here’s an example:
(source> *some-source :> %microbatch)
(<<batch
(%microbatch :> [*k *v])
(+group-by *k
(+sum *v :> *sum))
(materialize> *k *sum :> $$t))
(anchor> <s>)
(<<branch <s>
(<<batch
($$t :> *k *sum)
(println "Read materialized A: " *k *sum)
))
(<<branch <s>
(<<batch
($$t :> *k *sum)
(println "Read materialized B: " *k *sum)
))materialize> emits a PState that can then be referenced in other batch blocks. It accepts an arbitrary number of fields, and then reading that PState later emits the same number of fields. A materialized PState is read by using it as an operation within a batch block – this acts as a generator that emits all materialized values across all partitions of the PState.
Interacting with PStates
PStates are read and written in topologies through first-class operations in the dataflow API. Interaction is done using Specter paths. Rama contains an internal fork of Specter in the namespace com.rpl.rama.path that adds powerful reactive capabilities to them. For the most part, the internal and open-source versions are API-equivalent.
The basic operation for reading from a PState is local-select>. This reads from the PState partition colocated on the executing event’s current task. For example:
(local-select> [(keypath *user-id) ALL] $$p :> *v)Unlike the open-source Specter function select, which returns a sequence of navigated values, local-select> emits per navigated value. So if the path navigates to zero values, local-select> won’t emit at all. You can get a sequence of results with local-select> by wrapping the path in subselect, like so:
(local-select> (subselect (keypath *user-id) ALL) $$p :> *v)The second operation for reading from a PState is select>. select> is the same as local-select> except partitions the computation before performing the read, similar to how foreign-select chooses a target partition. This means the task before and after the select> call can be different. For example:
(select> [(keypath *user-id) ALL] $$p :> *v)If $$p is configured with the default key partitioner (hash-based), this is equivalent to:
(|hash$$ $$p *user-id)
(local-select> [(keypath *user-id) ALL] $$p :> *v)Yielding selects can be done with the :allow-yield? option, which breaks up the query into multiple events so as not to hold the task thread for an excessive amount of time. For example:
(local-select> [(keypath *user-id) ALL MAP-VALS] $$p {:allow-yield? true} :> *v)The basic operation for writing to a PState is local-transform>. Transform paths for this operation are like transform paths for multi-transform in open-source Specter. Terminal navigators in the path must be either term, termval, or NONE>. NONE> is equivalent to (termval NONE) and exists because NONE cannot be used in Rama dataflow code.
Here’s a few examples of using local-transform>:
(local-transform> [(keypath *user-id) (termval *profile)] $$profiles)
(local-transform> [(keypath *user-id) NONE-ELEM (termval *other-user-id)] $$followers)
(local-transform> [(keypath *user-id) MAP-VALS even? (term inc)] $$p)
(local-transform> [(keypath *user-id) :some-field NONE>] $$p2)
(<<ramafn %add-val
[*v]
(:> (+ *v 10)))
(local-transform> [(keypath *user-id) :some-field (term %add-val)] $$p2)That last example shows how you would apply arbitrary logic to a navigated value with <<ramafn, potentially using information in the closure.
Note that you should not store <<ramafn or <<ramaop anonymous operations directly in a depot or PState. The underlying class names for those operations are not stable between compilations, and you won’t be able to read those out of the depot or PState after a module update.
Another operation for writing to a PState is local-clear>. This should only be used on a top-level value PState, like with a schema Object, and resets the PState to its configured initial value.
Finally, you can also update PStates using aggregators. This specifies the write in terms of the shape of the data structure being written and automatically handles initializing non-existent locations. Under the hood, these callsites compile to local-transform> calls. You can either use aggregators directly or through +compound.
Integrating with Java API
Rama’s dataflow API has a couple facilities for integrating with utilities written using Rama’s Java API, like in the rama-helpers project.
The first is java-macro!, and this splices in code generated via the Java API into a block of Clojure API code. For example:
(java-macro! (.genId module-unique-id-pstate "*id"))
(local-transform> [(keypath *id) (termval *profile)] $$profile)The argument to java-macro! is a Clojure expression that resolves to a Block. The Java API specifies variables as strings, with the same naming format as Clojure API variables, so in this case the java-macro! call is binding a new variable called *id which is then in scope for subsequent dataflow code.
The second facility available handles the inverse situation of providing the Java API a Block from Clojure API defined dataflow code. This facility is java-block<-. For example:
(java-macro!
(.handleExpirations
topology-scheduler
"*id"
"*current-time-millis"
(java-block<-
(local-transform> [(keypath *id) (term inc)] $$p)
(local-transform> [(keypath *id) (termval true)] $$expirations)
)))There’s no difference in dataflow code written with java-block<- versus regular dataflow code.
Yielding thread
This section discusses how Rama topology execution breaks down into discrete events and the importance of individual events not holding the thread for too long. The Clojure API provides the operation yield-if-overtime analogous to the corresponding Java API method.
yield-if-overtime yields the thread if too much time has been taken by the current event (default 5ms). When computation resumes, it emits one time. Like other operations in Rama such as partitioners, you’re able to read the code linearly even though the execution of work is highly asynchronous.
Integrating non-blocking calls to external services
When writing a topology, it’s critical you never block a task thread by waiting on another thread or process. A task thread is used for depot appends, other topologies, PState queries, and internal system tasks. Blocking the task thread would block all those other functions from being carried out. So when you need to interact with a system running somewhere else, Rama’s dataflow API provides the operation completable-future> to do so in an efficient, non-blocking way.
completable-future> takes in a CompletableFuture object, and when the CompletableFuture delivers emits its result to :>. Here’s an example:
(completable-future> (my-remote-database-call *user-id) :> *res)
(local-transform> [:user-id (termval *res)] $$p)completable-future> efficiently ties the success of the asynchronous operation with the success of the topology. If the call succeeds, the value is delivered and the topology proceeds with whatever is after the completable-future> call. If the call fails by delivering an exception to the CompletableFuture, the topology will detect that failure and retry if appropriate.
completable-future> isn’t limited to usage with external systems. It’s a generic facility for integrating arbitrary asynchronous work within a topology.
Segmacros
Rama dataflow has a macro system called "segmacros" for making dataflow operations that expand to one or more dataflow segments. You can use Clojure macros as well, but segmacros are generally a more natural mechanism since they parse input/output streams for you. Segmacros work very differently than Clojure macros.
Segmacros return segments in the form of vector data. Let’s take a look at an example of using the most general-purpose segmacro operation, defbasicblocksegmacro.
(defbasicblocksegmacro bunch-of-ops [field1 field2 field3 :> out-var]
[[+ field1 field2 :> '*v#]
[* '*v# field3 :> out-var]])
(?<-
(bunch-of-ops 1 2 3 :> *v)
(println *v))This prints:
9bunch-of-ops is of course better written as a function. This example is just demonstrating the basics of segmacros.
The body of a segmacro is a normal Clojure function. defbasicblocksegmacro returns a sequence of segments as data. Variables are specified as explicit symbols, but otherwise the syntax of segments is the same. Any operations are used directly, as opposed to a Clojure macro which would use a symbolic reference to a function.
The binding vector of defbasicblocksegmacro parses the inputs and output declarations of the callsite into the specified arguments. Inputs and output declarations on a segmacro don’t have any further meaning with a segmacro besides syntax. You could use a field in an output declaration as an input into one of the generated segments, for example.
As you can see from this example, you can make generated variables local to the segmacro with the # suffix, just like you can with Clojure macros.
The phases of Rama dataflow compilation are:
-
Clojure macro expansion
-
Segmacro expansion
-
Bytecode compilation
Segmacros have some helpful facilities for expressing segments dynamically. The first is block>, which splices a sequence of segments into a larger sequence of segments. For example:
(defn helper* []
[[identity '*t# :> '*t2#]])
(defbasicblocksegmacro my-segmacro [:> out-var]
[[+ 1 2 :> '*t#]
[block> (helper*)]
[* '*t2# 2 :> out-var]])This is equivalent to:
(defbasicblocksegmacro my-segmacro [:> out-var]
[[+ 1 2 :> '*t#]
[identity '*t# :> '*t2#]
[* '*t2# 2 :> out-var]])block> is useful when generating segments dynamically.
Another useful facility is seg#, which makes it easy to specify a nested segment. The bunch-of-ops example can be written with this as:
(defbasicblocksegmacro bunch-of-ops [field1 field2 field3 :> out-var]
[[* (seg# + field1 field2) field3 :> out-var]])The return value of defbasicblocksegmacro is known to be a sequence of segments, so nothing needs to be done to distinguish segments from plain vector data for it. In a nested context, however, Rama has no way to tell that a plain vector is supposed to be a segment as opposed to an actual vector. seg# is used to distinguish the two cases.
Another helpful facility is :++fields for providing a vector of fields to an input or output stream. For example:
(defbasicblocksegmacro my-segmacro [:> out-var]
[[* :++fields [1 2 3] :> :++fields [out-var]]])This is useful when the fields are generated dynamically and is much easier than constructing the segment using operations like concat.
Generating vars
Rama has equivalents to gensym for generating Rama variables. These include:
defbasicsegmacro
defbasicsegmacro is just like defbasicblocksegmacro except only returns a single segment. For example:
(defbasicsegmacro bunch-of-ops [field1 field2 field3 :> out-var]
[* (seg# + field1 field2) field3 :> out-var])defblock
defblock provides a convenient way to write a segmacro that takes in a block of dataflow code as input. For example, here’s a simple segmacro that times the execution of a block of code:
(defn current-time-millis [] (System/currentTimeMillis))
(defblock <<time [label block]
[[current-time-millis :> '*t1]
[<<atomic [block> block]]
[current-time-millis :> '*t2]
[println label "elapsed:" (seg# - '*t2 '*t1) "ms"]
])
(?<-
(<<time "myblock"
(ops/range> 0 10 :> *v)
(ops/range> 0 *v :> *v2)
))defblock receives any number of input arguments, and the final argument will be a sequence of segments after the input arguments. block> is useful for splicing that code in with the generated segments.
The naming convention in Rama is to prefix the name of a defblock with <<. This indicates that the operation doesn’t make sense to be used in a nested segment and takes in a block of code as input.