Query topologies
Query topologies are a powerful facility in Rama enabling you to execute realtime, on-demand, distributed queries across any or all of your PStates and any or all of your tasks. They are similar in principle to predefined queries in SQL databases, except programmed with the same Java API as used to define ETLs and far more powerful.
PState clients have powerful capabilities for doing point queries where you fetch data from one partition of one PState. The Path API allows you to slice and dice your way through a PState no matter what data structure or combination of data structures it is. As powerful as this API is, there are many cases where your queries need to look at multiple PStates at the same time or aggregate data across many tasks. Query topologies elegantly provide this functionality.
You’ve seen how the dataflow API gives you great expressive power for processing data in order to create PStates. The basic dataflow primitives combined with higher level facilities like conditionals, loops, and batch blocks make even the most complex use cases elegant to implement. Query topologies use the exact same API to leverage that same elegance for query use cases.
All examples on this page can be found in the rama-examples project.
Structure of query topologies
Query topologies work like functions in regular programming. They take in any number of arguments as input and return exactly one object as output. Here’s a simple example of a query topology:
public class SimpleQueryModule implements RamaModule {
@Override
public void define(Setup setup, Topologies topologies) {
topologies.query("q", "*a", "*b").out("*res")
.each(Ops.PLUS, "*a", "*b", 1).out("*res")
.originPartition();
}
public static void main(String[] args) throws Exception {
try(InProcessCluster cluster = InProcessCluster.create()) {
RamaModule module = new SimpleQueryModule();
cluster.launchModule(module, new LaunchConfig(4, 4));
String moduleName = module.getClass().getName();
QueryTopologyClient<Integer> q = cluster.clusterQuery(moduleName, "q");
System.out.println("Query 1: " + q.invoke(1, 2));
System.out.println("Query 2: " + q.invoke(10, 7));
}
}
}As you can see the module definition is extremely small. The main method shows how a query topology is invoked from a client context. The query topology takes as input two numbers and returns the sum of the numbers plus one. The client invokes the query topology like any other function, by passing in two arguments and receiving a return value back. Unlike a regular function, the code runs remotely on a cluster. Running the main method prints:
Query 1: 4
Query 2: 18A query topology is defined by calling query on a Topologies object. query takes as input the name of the query topology followed by vars for the input arguments. A query topology can be defined with as few or as many arguments as you like, just like a Java function. Then the subsequent out call defines the output var for the topology. The rest of the code must ensure that var is in scope at the end.
Query topologies are implicitly batch blocks. So when programming them you’re always thinking in terms of pre-agg, agg, and post-agg phases. All the power of batch blocks, including joins, subbatches, and two-phase aggregation, is available. You can learn how to use batch blocks in this section. This example is a simple pre-agg only batch block.
All query topologies must contain originPartition, and that must be the final partitioner of the computation. This is a special partitioner that can only be used within query topologies. It indicates to partition back to the "origin", which is the initial task ID of the query. The output var must be in scope by the end of the computation, and it must be emitted exactly one time. If emitted zero times or more than once the query topology will error. For example, here’s a query topology that would have problems:
topologies.query("q", "*list").out("*res")
.originPartition()
.each(Ops.EXPLODE, "*list").out("*res");If the input list has exactly one element, "*res" will be emitted one time and the topology will work. Otherwise, "*res" will be emitted zero times or more than once and the topology will error.
Let’s take a look at an example of making a query topology for a more realistic use case. To start, let’s take a look at implementing "URL reach" on a social network. The reach of a URL is the number of unique users potentially exposed to a URL. It’s the distinct count of all the followers of all the people who ever shared that URL. To compute reach, you have to:
-
Fetch all the users who shared the URL
-
Fetch all the followers of all those users
-
Compute the distinct count of that set of followers
This computation can involve fetching the followers for thousands of users and then computing the distinct count of tens of millions of elements. To be fast, steps #2 and #3 must be parallelized. Here’s a module which implements this with a 13 line query topology:
public class ReachModule implements RamaModule {
private SubBatch partialReachCounts(String urlVar) {
Block b = Block.hashPartition(urlVar)
.localSelect("$$urlToUsers", Path.key(urlVar).all()).out("*userId")
.select("$$followers", Path.key("*userId").all()).out("*reachedUserId")
.hashPartition("*reachedUserId")
.agg(Agg.set("*reachedUserId")).out("*partialReachedSet")
.each(Ops.SIZE, "*partialReachedSet").out("*count");
return new SubBatch(b, "*count");
}
@Override
public void define(Setup setup, Topologies topologies) {
setup.declareDepot("*urlsDepot", Depot.hashBy(Ops.FIRST));
setup.declareDepot("*followsDepot", Depot.hashBy(Ops.FIRST));
MicrobatchTopology core = topologies.microbatch("core");
core.pstate(
"$$urlToUsers",
PState.mapSchema(
String.class,
PState.setSchema(String.class).subindexed()));
core.pstate(
"$$followers",
PState.mapSchema(
String.class,
PState.setSchema(String.class).subindexed()));
core.source("*urlsDepot").out("*microbatch")
.explodeMicrobatch("*microbatch").out("*tuple")
.each(Ops.EXPAND, "*tuple").out("*url", "*userId")
.compoundAgg("$$urlToUsers", CompoundAgg.map("*url", Agg.set("*userId")));
core.source("*followsDepot").out("*microbatch")
.explodeMicrobatch("*microbatch").out("*tuple")
.each(Ops.EXPAND, "*tuple").out("*userId", "*followerId")
.compoundAgg("$$followers", CompoundAgg.map("*userId", Agg.set("*followerId")));
topologies.query("reach", "*url").out("*numUniqueUsers")
.subBatch(partialReachCounts("*url")).out("*partialCount")
.originPartition()
.agg(Agg.sum("*partialCount")).out("*numUniqueUsers");
}
public static void main(String[] args) throws Exception {
try(InProcessCluster cluster = InProcessCluster.create()) {
RamaModule module = new ReachModule();
cluster.launchModule(module, new LaunchConfig(2, 2));
String moduleName = module.getClass().getName();
Depot urlsDepot = cluster.clusterDepot(moduleName, "*urlsDepot");
Depot followsDepot = cluster.clusterDepot(moduleName, "*followsDepot");
QueryTopologyClient<Integer> reach = cluster.clusterQuery(moduleName, "reach");
urlsDepot.append(Arrays.asList("grapefruit.com", "jamescagney"));
urlsDepot.append(Arrays.asList("grapefruit.com", "maeclarke"));
followsDepot.append(Arrays.asList("jamescagney", "joanleslie"));
followsDepot.append(Arrays.asList("jamescagney", "henryfonda"));
followsDepot.append(Arrays.asList("jamescagney", "arlenefrancis"));
followsDepot.append(Arrays.asList("jamescagney", "jacklemmon"));
followsDepot.append(Arrays.asList("maeclarke", "henryfonda"));
followsDepot.append(Arrays.asList("maeclarke", "charleslaughton"));
followsDepot.append(Arrays.asList("maeclarke", "joanleslie"));
followsDepot.append(Arrays.asList("maeclarke", "debbiereynolds"));
cluster.waitForMicrobatchProcessedCount(moduleName, "core", 10);
System.out.println("grapefruit.com reach: " + reach.invoke("grapefruit.com"));
}
}
}Reach operates on two PStates, "$$urlToUsers" and "$$followers". The first maps a URL to the set of users who shared that URL, and the second maps each user to the set of all their followers. The topology "core" maintains these PStates based on events from "*urlsDepot" and "*followsDepot". In a real application you wouldn’t have a depot like this containing URL/user pairs directly – instead you would consume a depot containing the full content of posts and extract the URLs from the posts in the topology. Since the focus of this example is implementing "reach", it’s done this way for simplicity.
The "reach" topology takes in as input one argument, a URL. In the main method you can see it’s invoked from a client like a regular Java function with the code reach.invoke("grapefruit.com"). This launches a distributed computation to compute the reach for "grapefruit.com".
The topology parallelizes both the fetching of the followers and the computation of the distinct count. The fetched followers are partitioned into sets across all the tasks of the module, and then the counts of those sets are summed to compute the final result. The partialReachCounts subbatch computes the partial counts, and those partial counts are summed afterwards by the top-level block.
The key to this code is the .hashPartition("*reachedUserId") call. When the same follower exists across multiple users, this code sends all emits of that follower to the same task for aggregation. Since it’s a hash partition, the followers are still evenly divided across the tasks which ensures a balanced parallel computation. You can visualize the execution of the "grapefruit.com" query in the example like so:
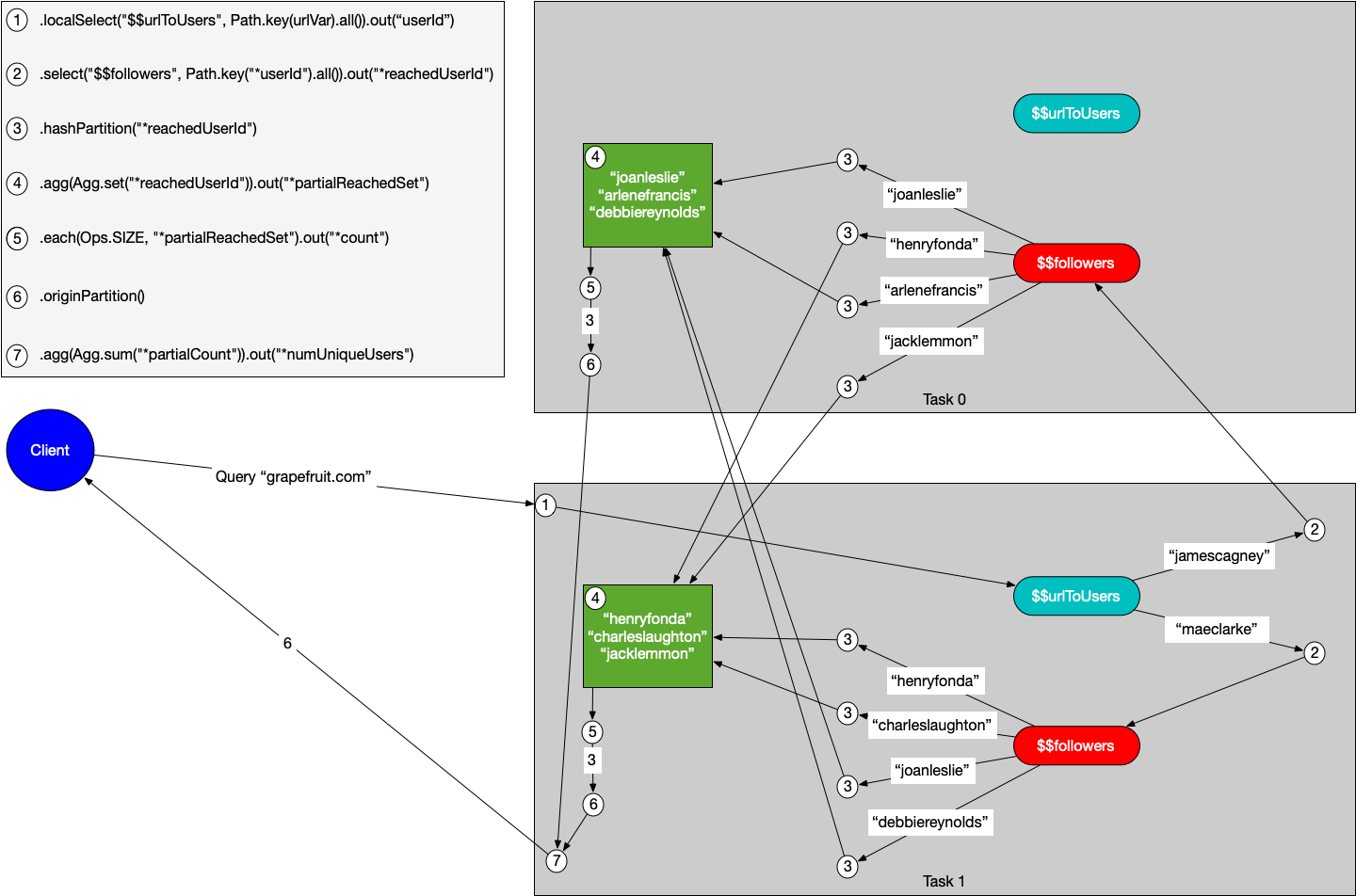
The values of the user IDs don’t necessarily hash to the tasks indicated – this is just an illustration of how the work gets divided up. Notice how the set aggregation on task 0 receives "joanleslie" twice, and the set aggregation on task 1 receives "henryfonda" twice. Since they’re aggregating to a set, they only get counted once when the set is counted.
This example parallelizes the computation across two tasks. The more tasks in your module, the more parallelism the query will have.
Running the main method performs this computation and prints:
grapefruit.com reach: 6What’s even better about this query topology is the efficiency it achieves from its colocation with the "$$urlToUsers" and "$$followers" PStates. When it performs select calls on those it’s doing local computation on the thread. This is a level of efficiency only possible with an integrated system like Rama.
Not every query topology will be an intensive distributed computation like this one. Many just need to go to one task and combine information across multiple PStates, or they just need to aggregate a small amount of data across multiple tasks. What "URL reach" demonstrates is how easy it is to implement even a sophisticated use case.
Query topology client
A query topology client is retrieved from RamaClusterManager on a real cluster, or from InProcessCluster in a test environment. Connecting to a Rama cluster to fetch query topology clients is discussed more on this page.
In the examples so far you’ve already seen how to fetch a QueryTopologyClient and use it through its invoke method. invoke errors if you pass a different number of arguments than specified in the topology definition. Otherwise, it blocks until the query is complete.
Like how PStates have non-blocking versions of select, selectOne, and proxy, there’s also a non-blocking version of invoke called invokeAsync. This returns a CompletableFuture that will be delivered on completion of the query topology. For example, invokeAsync could be used with the "URL reach" client like so:
CompletableFuture<Long> res = reach.invokeAsync("grapefruit.com");You can then use the CompletableFuture API to add callbacks for what to do when it’s delivered.
Invoking a query topology could fail for a variety of reasons: your topology code throws an exception, one of the cluster machines goes down in the middle of the computation, or the request times out. In these cases invoke will throw an exception and invokeAsync will deliver an exception to the CompletableFuture with completeExceptionally.
Leading partitioner optimization
When you invoke a query topology client, it must first decide on which task to start executing. Many query topologies start by querying from a particular PState (like the "URL reach" topology above), and a query topology can save multiple network hops by starting on the right task. Query topologies implement a "leading partitioner optimization" that lets you achieve this.
When a query topology starts with an appropriate partitioner call, the partitioner will execute client-side before the invoke request is sent to the module. A partitioner is leading if it’s the first call of the query topology, whether at the top-level of the topology definition or in a subbatch. So in the "URL reach" topology above, the call to .hashPartition(urlVar) is a leading partitioner. Execution of the topology always begins on the task containing the data for the URL in question.
There are a few minor restrictions on which partitioners can be leading for the purposes of the optimization:
-
Must be a built-in partitioner (e.g.
hashPartition) and can’t be a custom partitioner -
Must be a partitioner that goes to exactly one task (e.g.
.allPartitioncannot be a leading partitioner) -
All input to the partitioner call must be input vars for the query topology
-
Cannot be a state partitioner to a mirror PState
-
Although
selectin a topology implicitly inserts a partitioner, that partitioner will not count as a leading partitioner. This is why "URL reach" does ahashPartitionfollowed by alocalSelectinstead of aselect.
If a query topology does not have a leading partitioner, the starting task will be selected at random.
Especially for query topologies which don’t do that much computation, like one that fetches data from multiple PStates from one task, the leading partitioner optimization can have a big impact on performance.
Invoking colocated query topologies
Query topologies can be called from other topologies in the same module, whether other query topologies or ETL topologies. They’re another way to decompose the logic of your module.
A colocated query topology can be invoked with the Block method invokeQuery. It takes as input the topology name to invoke along with the arguments. Here’s an example of using this:
public class ColocatedQueryTopologyInvokeModule implements RamaModule {
@Override
public void define(Setup setup, Topologies topologies) {
topologies.query("q1", "*a").out("*res")
.each(Ops.TIMES, "*a", 3).out("*res")
.originPartition();
topologies.query("q2", "*a").out("*res")
.invokeQuery("q1", "*a").out("*v")
.each(Ops.PLUS, "*v", 1).out("*res")
.originPartition();
}
public static void main(String[] args) throws Exception {
try(InProcessCluster cluster = InProcessCluster.create()) {
RamaModule module = new ColocatedQueryTopologyInvokeModule();
cluster.launchModule(module, new LaunchConfig(4, 4));
String moduleName = module.getClass().getName();
QueryTopologyClient<Integer> q2 = cluster.clusterQuery(moduleName, "q2");
System.out.println("Query 1: " + q2.invoke(1));
System.out.println("Query 2: " + q2.invoke(10));
}
}
}Running this prints:
Query 1: 4
Query 2: 31You can also call query topologies from topologies in other modules. This is described on this page.
Recursive query topologies
Query topologies can also be recursive by invoking themselves. Here’s an example of implementing the "nth fibonacci number" in a query topology:
public class FibonacciModule implements RamaModule {
@Override
public void define(Setup setup, Topologies topologies) {
topologies.query("fib", "*n").out("*res")
.ifTrue(new Expr(Ops.OR, new Expr(Ops.EQUAL, "*n", 0),
new Expr(Ops.EQUAL, "*n", 1)),
Block.each(Ops.IDENTITY, 1).out("*res"),
Block.invokeQuery("fib", new Expr(Ops.DEC, "*n")).out("*a")
.invokeQuery("fib", new Expr(Ops.MINUS, "*n", 2)).out("*b")
.each(Ops.PLUS, "*a", "*b").out("*res"))
.originPartition();
}
public static void main(String[] args) throws Exception {
try(InProcessCluster cluster = InProcessCluster.create()) {
RamaModule module = new FibonacciModule();
cluster.launchModule(module, new LaunchConfig(4, 4));
String moduleName = module.getClass().getName();
QueryTopologyClient<Integer> fib = cluster.clusterQuery(moduleName, "fib");
for(int i=0; i<10; i++) {
System.out.println("Fib(" + i + "): " + fib.invoke(i));
}
}
}
}Running this prints:
Fib(0): 1
Fib(1): 1
Fib(2): 2
Fib(3): 3
Fib(4): 5
Fib(5): 8
Fib(6): 13
Fib(7): 21
Fib(8): 34
Fib(9): 55Query topologies can also be mutually recursive.
Rama provides protection against infinite recursion were you to have a bug like that in your code. Since query topologies are always invoked with a timeout, that timeout is used on internal events to halt computation if it’s exceeded. The query topology invocation can still use a lot of resources during that time period, but at least it won’t use resources forever.
Temporary in-memory state for query topologies
More complex query topologies sometimes need to track in-memory state across tasks during their execution. Rama provides an implicit PState for this purpose for every query topology called "$$<query topology name>$$". So if you have a query topology called "findPath", the implicit PState is called "$$findPath$$". The values of this PState’s partitions are unique for every query topology invoke, and each partition starts as null.
Here’s an example of using this implicit in-memory PState in a query topology:
public class TemporaryQueryStateModule implements RamaModule {
@Override
public void define(Setup setup, Topologies topologies) {
topologies.query("foo", "*v", "*v2").out("*res")
.hashPartition("*v")
.localTransform("$$foo$$", Path.termVal("*v2"))
.shufflePartition()
.hashPartition("*v")
.localSelect("$$foo$$", Path.stay()).out("*v3")
.originPartition()
.each(Ops.PLUS, "*v", "*v3").out("*res");
}
public static void main(String[] args) throws Exception {
try(InProcessCluster cluster = InProcessCluster.create()) {
RamaModule module = new TemporaryQueryStateModule();
cluster.launchModule(module, new LaunchConfig(4, 2));
String moduleName = module.getClass().getName();
QueryTopologyClient<Integer> foo = cluster.clusterQuery(moduleName, "foo");
System.out.println("Result: " + foo.invoke(2, 3));
System.out.println("Result: " + foo.invoke(2, 4));
System.out.println("Result: " + foo.invoke(3, 5));
}
}
}This is computing the sum of two numbers in a contrived way by storing the second number in the temporary PState, hopping around to different partitions of the module, and then coming back to the task with the stored state to complete the sum.
Tuning options
Dynamic options can be edited from the Cluster UI and take effect immediately. They can be configured on a topology by topology basis. The dynamic option available for query topologies is:
-
topology.query.timeout.millis: This is the timeout used for a query topology’s execution.
Summary
To design an application you must determine the balance of what information gets precomputed into PStates and what gets computed at query time. Rama’s ETL and PState abstractions give you fantastic capabilities for doing the former, and query topologies give you fantastic capabilities for doing the latter. They allow the query side of applications to be distributed computations as well, and by using the exact same API as ETL topologies they are extremely flexible and easy to write.