Stream topologies
In the tutorial, you learned the basics of using stream topologies. You saw how stream topologies reactively process data from depots, and you saw how easy it is to configure stream topologies to process from as many depots as you need. In this section, we’ll go beyond the basics to show everything there is to know about stream topologies, including:
-
Internal state kept by stream topologies and how it’s updated
-
Fault-tolerance of stream topologies and different retry behaviors available
-
Configuring where a new stream topology starts processing from a depot
-
How stream topologies throttle processing to avoid being overloaded
-
Tuning options available for stream topologies
All examples on this page can be found in the rama-examples project.
Usage
Stream topologies can create any number of PStates and consume data from any number of depots. They typically finish processing a depot record within a few milliseconds. Let’s take a look at this example:
public class BasicStreamTopologyModule implements RamaModule {
@Override
public void define(Setup setup, Topologies topologies) {
setup.declareDepot("*depot", Depot.hashBy(Ops.FIRST));
setup.declareDepot("*depot2", Depot.random());
StreamTopology s = topologies.stream("s");
s.pstate("$$p1", PState.mapSchema(String.class, Long.class));
s.pstate(
"$$p2",
PState.mapSchema(
String.class,
PState.mapSchema(String.class, Long.class).subindexed()));
s.source("*depot").out("*tuple")
.each(Ops.EXPAND, "*tuple").out("*k1", "*k2")
.compoundAgg("$$p1", CompoundAgg.map("*k1", Agg.count()))
.compoundAgg("$$p2", CompoundAgg.map("*k1", CompoundAgg.map("*k2", Agg.count())))
.ifTrue(new Expr(Ops.NOT_EQUAL, "*k1", "*k2"),
Block.hashPartition("*k2")
.compoundAgg("$$p1", CompoundAgg.map("*k2", Agg.count()))
.compoundAgg("$$p2", CompoundAgg.map("*k2", CompoundAgg.map("*k1", Agg.count()))));
s.source("*depot2").out("*v")
.each(Ops.CURRENT_TASK_ID).out("*taskId")
.each(Ops.PRINTLN, "From *depot2:", "*taskId", "*v");
}
public static void main(String[] args) throws Exception {
try(InProcessCluster cluster = InProcessCluster.create()) {
RamaModule module = new BasicStreamTopologyModule();
cluster.launchModule(module, new LaunchConfig(4, 4));
String moduleName = module.getClass().getName();
Depot depot = cluster.clusterDepot(moduleName, "*depot");
Depot depot2 = cluster.clusterDepot(moduleName, "*depot2");
PState p1 = cluster.clusterPState(moduleName, "$$p1");
PState p2 = cluster.clusterPState(moduleName, "$$p2");
depot.append(Arrays.asList("a", "b"));
depot.append(Arrays.asList("b", "c"));
depot.append(Arrays.asList("a", "a"));
System.out.println("a count: " + p1.selectOne(Path.key("a")));
System.out.println("b count: " + p1.selectOne(Path.key("b")));
System.out.println("c count: " + p1.selectOne(Path.key("c")));
System.out.println("b subcounts: " + p2.select(Path.key("b").all()));
depot2.append("X");
depot2.append("Y");
}
}
}This module produces PStates "$$p1" and "$$p2" that track counts from data coming from "*depot". "$$p2" stores counts for each pair of keys. "*depot" emits tuples containing two keys, and the counts are incremented for each key. Except for batch blocks, the entire dataflow API is available to you in stream topologies. Conditionals, loops, branching, and unification can be used freely. This module uses a condition to only increment counts for the reverse combination of keys if the keys are not equal. Partitioners can be used inside conditionals, and they can also be used in loops or any other dataflow construct.
Running the main method prints:
a count: 2
b count: 2
c count: 1
b subcounts: [["a" 1] ["c" 1]]
From *depot2: 3 X
From *depot2: 0 Y"*depot2" is included just to demonstrate consuming from multiple depots. When consuming multiple depots from a topology, it’s typical for each source block to modify the same PStates in different ways.
Because batch blocks cannot be used in stream topologies, stream topologies are unable to benefit from two-phase aggregation. This makes it difficult to do efficient global aggregation in stream topologies. If you want efficient global aggregation, you should generally prefer microbatch topologies.
Stream topologies have deep integration with depot appends. Depot appends as shown in this example will block until all colocated stream topologies have finished processing the data. There are other "ack levels" you can use on depots if you want different behavior – see the page on depots for more details.
Multi-source
As of Rama 1.2.0, topologies can consume from the same depot multiple times. To do so, additional source blocks must be given a unique "source ID" that’s used to keep track of the progress of that source and to continue where it left off after a module update. A source ID is specified like so:
s.source("*depot", StreamSourceOptions.sourceId("mySourceId")).out("*data")Each source can have its own "start from" options set, and they process the depot independently. Once they get close enough, they will sync and then atomically process data together. When a topology consumes from any depot multiple times, the Cluster UI for the topology has an additional chart indicating whether sources are synced or not that looks like:

Once the sources are synced, the module can be safely updated to remove the multiple sources and combine the code into one source.
Note that for stream topologies, multi-source can only be used when the retry mode is configured as "individual" or "all after".
Operation
Understanding how Rama executes stream topologies can help you understand its fault-tolerance model and the key factors impacting performance. Let’s look at a broad overview of how they work.
After a depot partition appends a new record, it pushes that record to all subscribed stream topologies. This includes colocated stream topologies as well as stream topologies from other modules.
Colocated stream topologies carefully track every depot record being processed. Depending on the implementation of the stream topology, processing a single depot record can trigger many downstream events across many tasks across the module. Facilities like conditionals and loops can make the amount of downstream processing dynamic. The downstream work forms an "event tree", and a stream topology can only mark a depot record as processed when the event tree has been exhausted and each individual event in the tree has completed. For example, consider the following source block of a stream topology:
s.source("*depot").out("*k")
.anchor("root")
.hashPartition("*k")
.localTransform("$$p", Path.key("*k").termVal("XYZ"))
.hook("root")
.shufflePartition()
.ifTrue(new Expr(Ops.EQUAL, "*k", "A")
Block.each(Ops.RANGE, 0, 2).out("*i")
.hashPartition("*i")
.localTransform("$$p", Path.key("*i").termVal("*k")))See this section for a discussion of how a topology breaks down into events. The event tree for this code for the depot record "A" would be:
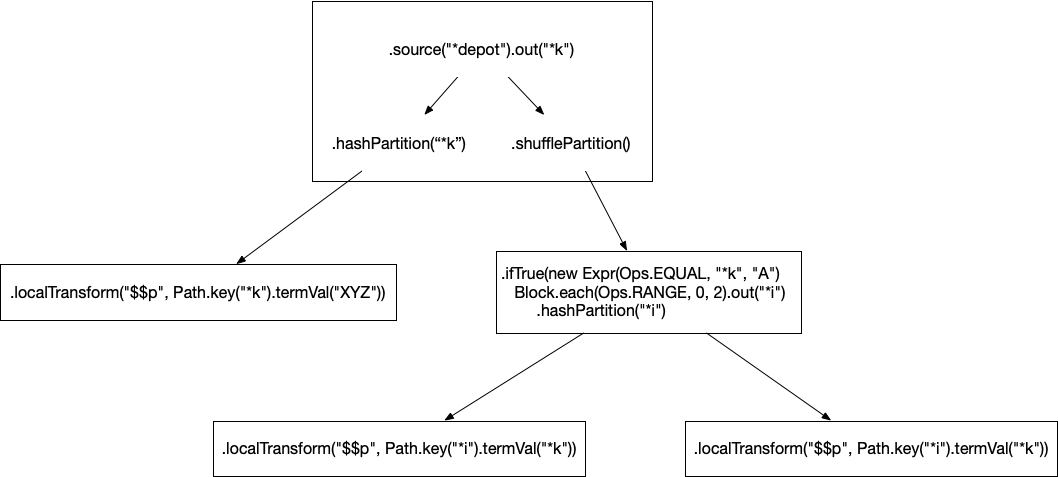
Each of those events could run on different tasks on different nodes across the cluster. Rama efficiently tracks these event trees, no matter how big or dynamic, with just a tiny bit of metadata called the "ack val" at the root of processing and with each event. In this case, you can see the initial event branches into both a hashPartition and shufflePartition creating two outgoing events. The RANGE call emits two times, creating two outgoing events from that event.
An individual event could do an arbitrary number of reads and writes to PStates on its task. The event doing the writing will be able to read its writes immediately, but PState clients and other topologies will not see those writes applied until after the event has finished and those writes have finished replicating. That writes are made externally visible on an event by event basis in stream topologies is different than how microbatch topologies work.
Execution of stream topology events on tasks are batched. All task threads for a module have a queue for pending events. While an event is executing, many events can queue up for a variety of work: stream and microbatch topology events, PState reads, system events, and so on. When it’s time to process a stream topology on a task, there could be many events queued up for that stream topology belonging to many event trees. To greatly improve performance, Rama batches the processing of those events together. All writes to PStates across all those events are buffered, applied, and replicated together. This means all writes across all events in a batch become visible externally at the same time. If your incoming throughput of data is low, these batches will be small (even as small as one event). If your incoming throughput of data is much higher, the batch sizes would be bigger because more stream topology events would queue up on a task while other events are running. This auto-batching behavior by Rama gives you the best of both worlds of latency and throughput for stream processing.
All writes to PStates from all events during one of these batches are made visible at the same time. So when you write to multiple PStates in the same event, you’re guaranteed either all writes or none of the writes are visible at any given moment.
Stream topologies track progress with an internal PState with a name of the form "$$__streaming-state-<topologyId>". In the example from the previous section, the PState would be called "$$__streaming-state-s". Each partition of this PState tracks progress on colocated depot partitions by the stream topology, and this PState enables a stream topology to pick up where it left off after a module update or a leader switch. Telemetry for this PState can be viewed in the Cluster UI. Because it would be inefficient to write to this PState after every depot record finishes processing, it is only written to after a configurable number of records have been processed or a configurable amount of time has passed. This has implications for how stream topologies handle fault-tolerance, which we’ll look at in the next section.
Fault-tolerance and "retry modes"
A topology event can fail for many reasons. One of the machines involved in processing could lose power, there could be a disk error, or there could be a bug in your code. Any exception thrown anywhere in the processing of a depot record will cause that topology event to retry processing of that record according to the configured "retry mode". Failures are rare, but it’s important you think through how they will be handled and how they can affect your PStates.
A "retry mode" is configured on a source by source basis. There are three retry modes available: "individual", "all after", and "none". A retry mode can be configured like so:
s.source("*depot", StreamSourceOptions.retryNone())
s.source("*depot2", StreamSourceOptions.retryAllAfter())Whenever a record is retried, it’s retried from the start of the corresponding source block. A depot record is never partially retried – even if it failed at the end of the topology code it will retry from the start of processing. So if retries are enabled, Rama guarantees "at least once processing" semantics for stream topologies. This means that during failures a depot record could cause multiple writes to the same PState. Write operations that are idempotent, like adding to a set, are unaffected by this. But non-idempotent write operations like incrementing a counter can become inaccurate from retries. This is a tradeoff for the extremely low latency of stream topologies. If perfect accuracy is critical for a use case like this, consider using a microbatch topology instead.
The default retry mode is "individual". In this mode, only depot records that failed to process are retried. Rama will try its best to retry records in the order in which they were appended, but because processing is asynchronous and distributed it can’t guarantee this.
The "none" retry mode never retries failed records. This retry mode has "at most once" processing semantics.
The final retry mode is "all after". In this mode a failed record will cause all records after it on the same depot partition to also be retried (even if they already succeeded). If the order of processing is critical, like processing "Follow" and "Unfollow" records for a social graph, this mode is appropriate.
Exceptions aren’t the only thing that can cause the processing of a record to fail. Rama also fails a record if its event tree doesn’t succeed within a configurable timeout. This handles scenarios like a downstream machine losing power in the middle of processing.
The way stream topologies checkpoint their progress on depot partitions also has implications for what records get retried. If a leader restarts or suddenly loses leadership after it has successfully processed some records but before it has checkpointed that progress, those records will get retried.
Because stream topology events are batched together for execution on a task thread, if any one of those events throws an exception all the events will fail. These events could be for processing triggered by depot records from many tasks across the module. So one of those events failing could lead to many depot records retrying across many tasks. Note that this behavior is unrelated to timeouts since timeouts are tracked on depot partitions at the root of event trees.
Lastly, if an exception is thrown or the process crashes during execution of a stream topology event, all PState writes during that batch of execution will be discarded. They will never replicate or be made visible externally. Subsequent retries from the depot sources for event trees involved in that batch will redo those writes.
"Start from" options
The first time a stream topology processes a depot partition (whether when the module is first launched or if a new depot source is added on a module update), it must determine where to start processing from that partition. By default it starts processing from the end, meaning it only processes records added to the partition after the topology started. However, there are a variety of options for starting from somewhere else.
Here are examples of all the different options you can configure:
s.source("*depot", StreamSourceOptions.startFromBeginning())
s.source("*depot2", StreamSourceOptions.startFromOffsetAfterTimestamp(107740800000))
s.source("*depot3", StreamSourceOptions.startFromOffsetAgo(10000, OffsetAgo.RECORDS))
s.source("*depot4", StreamSourceOptions.startFromOffsetAgo(15, OffsetAgo.DAYS))startFromBeginning starts processing from the first record available on the depot partition. startFromOffsetAfterTimestamp starts from the first record appended after that timestamp. startFromOffsetAgo lets you start from either a fixed number of records or a set amount of time in the past. See the Javadoc for OffsetAgo for all the options.
These options can be combined with retry options using the builder pattern, like so:
s.source("*depot", StreamSourceOptions.startFromBeginning().retryNone())Keep in mind that "start from" options only apply the first time the topology runs on a depot partition. After a leader switch or module update it will continue from where it left off.
"Ack return agg" options
Depot appends done with AckLevel.ACK wait for all colocated stream topologies consuming that depot to finish processing the appended data. Additionally, those colocated stream topologies can return arbitrary information as part of processing to the appender of that data. This is done with the ackReturn method.
Values given to ackReturn are aggregated on the task where processing began for that depot record. By default, the aggregation method used chooses the last value aggregated. Here’s an example of using an ack return to return the value updated in a PState during processing:
public class BasicAckReturnModule implements RamaModule {
@Override
public void define(Setup setup, Topologies topologies) {
setup.declareDepot("*depot", Depot.hashBy(Ops.IDENTITY));
StreamTopology s = topologies.stream("s");
s.pstate("$$p", PState.mapSchema(String.class, Long.class));
s.source("*depot").out("*k")
.compoundAgg("$$p", CompoundAgg.map("*k", Agg.count()))
.localSelect("$$p", Path.key("*k")).out("*v")
.ackReturn("*v");
}
public static void main(String[] args) throws Exception {
try(InProcessCluster cluster = InProcessCluster.create()) {
RamaModule module = new BasicAckReturnModule();
cluster.launchModule(module, new LaunchConfig(4, 2));
String moduleName = module.getClass().getName();
Depot depot = cluster.clusterDepot(moduleName, "*depot");
System.out.println("Ack return 1: " + depot.append("a"));
System.out.println("Ack return 2: " + depot.append("a"));
System.out.println("Ack return 3: " + depot.append("a"));
}
}
}Running this prints:
Ack return 1: {"s" 1}
Ack return 2: {"s" 2}
Ack return 3: {"s" 3}As you can see, the return of depot appends with AckLevel.ACK (which is the default if not specified) is a map from topology name to ack return value. Here there’s only one colocated stream topology providing an ack return, so the map contains just the one entry. In this example, for each depot append of the same key, the ack return value increases by one.
How ack return values are aggregated can be customized in the source options for a depot subscription. The ack return aggregator is specified using aggregators, whether a built-in aggregator or a custom one defined with RamaCombinerAgg or RamaAccumulatorAgg1.
Here’s an example that uses the built-in "sum" aggregator for ack returns:
public class SumAckReturnModule implements RamaModule {
@Override
public void define(Setup setup, Topologies topologies) {
setup.declareDepot("*depot", Depot.hashBy(Ops.IDENTITY));
StreamTopology s = topologies.stream("sumTopology");
s.source("*depot", StreamSourceOptions.ackReturnAgg(Agg::sum)).out("*v")
.each(Ops.RANGE, 0, "*v")
.shufflePartition()
.ackReturn("*v");
}
public static void main(String[] args) throws Exception {
try(InProcessCluster cluster = InProcessCluster.create()) {
RamaModule module = new SumAckReturnModule();
cluster.launchModule(module, new LaunchConfig(8, 3));
String moduleName = module.getClass().getName();
Depot depot = cluster.clusterDepot(moduleName, "*depot");
System.out.println("Ack return for 3: " + depot.append(3));
System.out.println("Ack return for 5: " + depot.append(5));
System.out.println("Ack return for 10: " + depot.append(10));
}
}
}Running this prints:
Ack return for 3: {"sumTopology" 9}
Ack return for 5: {"sumTopology" 25}
Ack return for 10: {"sumTopology" 100}The many ack return values are coming from random tasks in this example, but they all get summed together properly.
Using a custom aggregator just requires passing an instance of that aggregator, such as StreamSourceOptions.ackReturnAgg(new MyAggregator()). Using a custom aggregator allows for totally arbitrary logic to be plugged in for the ack return value aggregation. A custom aggregator also allows the start value of aggregation to be specified.
Throttling
Stream topologies place a limit on how many depot records can be processing at any given time. This is done to protect the module from being overloaded with data. If the incoming rate of data were much greater than what the topology could handle, memory usage would go up as more and more events backed up on internal queues. Eventually this would lead to out of memory errors and outages.
Since all depot records are tracked anyway as they’re out for execution by a topology, stream topologies throttle at the depot level. If the limit is set to 1000, at most 1000 records can be pending completion for a given task. As soon as a depot record succeeds or fails processing (including timeouts), one more depot record is allowed to be emitted for processing on that task by the topology.
When the limit is hit, the depot will wait for pending records to complete before emitting any more records. Depot appends with AckLevel.ACK while the limit is hit will throw an exception back to clients. In these cases the appends will have gone through, but since it was unable to start stream processing for at least one of the colocated stream topologies it returns immediately to clients with an exception rather than wait an indeterminate amount of time. Lastly, when the limit is hit those records will be skipped entirely for stream topologies with retryNone set for that depot source.
You should make sure to scale your modules such that stream topologies operate well under the limit in normal operation. For a healthy topology that limit should only be hit in unusual situations like sudden, temporary bursts of inbound traffic.
Tuning options
Many references were made on this page to configurations for various aspects of stream topology operation. This section will list all configurations and dynamic options relevant to stream topologies.
Configurations
Configurations are fixed upon module deploy and can only be changed with a module update. They cannot be customized on a topology by topology basis. There is only one configuration of this type for stream topologies:
-
topology.stream.periodic.checkpoint.seconds: Progress on depot partitions is written at this frequency regardless of how much progress has been made. This ensures that progress is written for low throughput depots at a predictable rate.
Dynamic options
Dynamic options can be edited from the Cluster UI and take effect immediately. They can be configured on a topology by topology basis. The dynamic options available for stream topologies are:
-
topology.stream.checkpoint.progress.threshold: Progress on depot partitions is written after this many depot records from the last checkpointed offset have succeeded. -
topology.stream.max.events.per.batch: This is the max number of stream topology events to batch together when executing stream topology events on a task. -
topology.stream.max.executing.per.task: This is the max number of depot records that can be pending for a stream topology for each task. Importantly, this is not a global number but a per task number. This option is what throttles stream topologies to protect the module from being overloaded. -
topology.stream.timeout.seconds: This is the timeout for each event tree to complete successfully. -
depot.cache.cardinality: Stream topologies utilize a cache on depots so they don’t have to re-read records from disk to perform retries. This config determines the size of that cache. -
depot.cache.catchup.chunk.size: When filling the depot cache, this config determines how many depot records to fetch at a time. This is relevant when a stream topology is far behind processing on a depot. -
depot.max.pending.streaming.per.partition: This is how many acked depot appends can be tracked per depot partition. -
depot.ack.failure.on.any.streaming.failure: Determines whether an acked depot append should be considered failed if any colocated streaming topology fails on the first attempt, or if it should give stream topologies a chance to succeed on retries. This defaults to true, and when false acked depot appends will only fail due to timeout or passing the max pending limit. Note that this option doesn’t affect stream topologies with retry mode of "none" whose failure will always cause acked depot appends to immediately fail.
Summary
Stream topologies are appropriate when you need millisecond-level latency for updating your PStates. Their integration with depot appends makes them great for coordinating work with front-end clients. You’ve seen how stream topologies give you great flexibility in how failures should be handled.
Though stream topologies cannot handle as high throughput as microbatch topologies due to the overhead of tracking each depot record individually, the use of batching within Rama’s implementation still gives them great performance. All those optimizations happen automatically in the background, and as a developer you’re able to take advantage of intuitive semantics for interacting with PStates.