Dataflow programming
To perform work in Rama, you write ETL and query topologies using Rama’s dataflow API. This chapter will explain the dataflow programming paradigm that the API embodies, and it will show you how to use all the elements of the API.
The dataflow programming paradigm
Dataflow programming can be understood in contrast to imperative programming, the industry-dominant paradigm that you probably have experience with.
You can think of imperative programming as defining a sequence of instructions to a worker for them to carry out: add these numbers, assign the result to this variable, call this method. You can see this physically embodied in something like a robot, where commands direct the robot’s behavior: turn to the right, walk forward four feet, turn to the left.
By contrast, dataflow programming is like constructing an assembly line. Each worker on the line waits for an input, performs an operation on it, and sends zero or more outputs to zero or more other workers. You can represent the relationships between workers as a directed graph, and you can refer to this graph as a dataflow pipeline. In Rama, we call these graphs topologies.
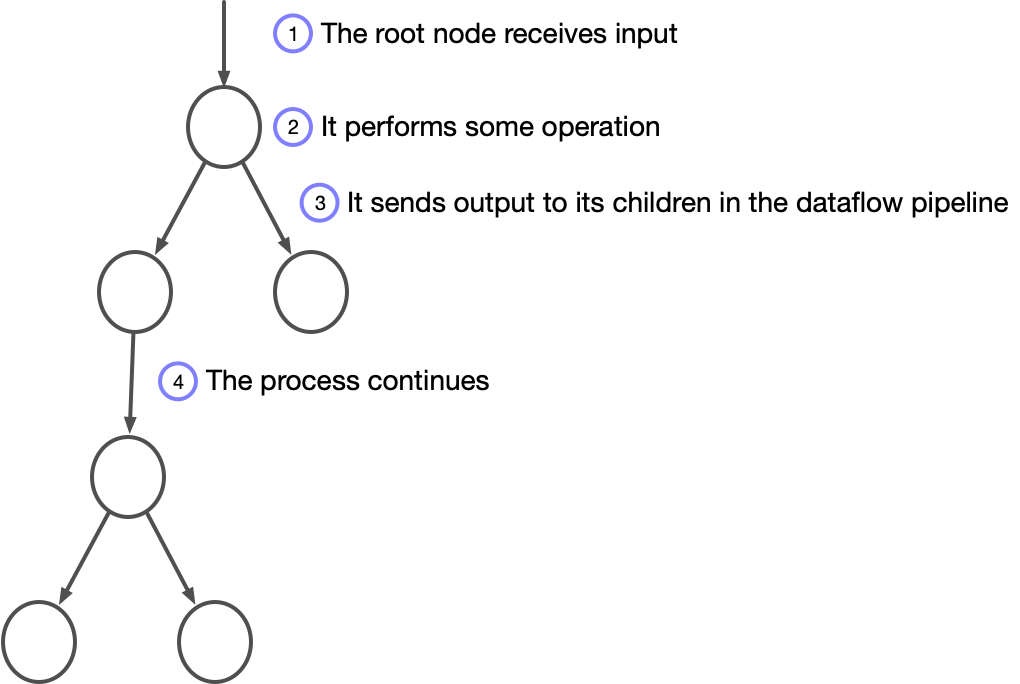
Dataflow programming can feel weird at first. Our usual way of constructing work is to give a kind of ontological primacy to subjects over verbs. It’s natural to think of the world as consisting of agents performing actions rather than as processes that entities flow through. It somehow feels more natural to think of a robot carrying out commands then it does to think of a network of nodes modifying data as it "flows" through.
Weird or not, it’s a great model for distributed programming. Dataflow is an extremely expressive way to map code to multiple cores or machines, which is why the Rama topology API was created.
Operations, input and output
Once again, we can understand the dataflow paradigm by comparing it to the imperative paradigm.
When an imperative program runs, its main thread of execution will start by
calling some method (or function if you’re not using an OO language; since Rama
is built on Java, let’s stick to talking about methods). Let’s call this Method
A. Method A might in turn call Method B, which calls Method C, and so
forth. Eventually, each of the method calls in this nested chain will return a
value, until Method A returns a value. The main thread of execution will then
move forward and call the next method, Method A', and the same process will
play out.

Our mental model for an imperative program consists of caller methods coordinating with callee methods by passing in arguments and waiting for a single return value. This relationship is so ingrained that we can take it for granted. In fact, it may feel strange to draw attention to it or to refer to the relationship as "coordination", but it’s helpful to look at it that way because it helps with understanding the dataflow paradigm.
On an abstract level, the process of programming involves decomposing a system into functional units like methods, and then getting those units to coordinate in some way. With imperative languages, that coordination happens via the callstack. Because it happens implicitly, and because it’s so pervasive, it’s easy to gain the sense that it’s "the" way that programs work.
However, it’s not the only way for you to coordinate functional units. In a dataflow program, you think in terms of operations that wait for input. Upon receiving input, they perform some work and emit output values to one or more other operations.
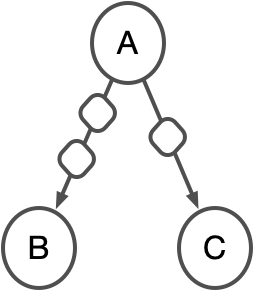
The corresponding program could be written so that when Operation A receives
an input, it emits two output values to Operation B and one output value
Operation C. Operation B would perform its work for each of the two inputs
it receives, and Operation C would perform its work the single value it
receives. These operations don’t return a value to Operation A.
There are already some pronounced differences with an imperative program:
-
In an imperative program, there’s a tight coupling between what gets done and how it happens: a main execution thread drives the process. In a dataflow program, the mapping between operations and threads is an implementation detail.
-
Dataflow programs are reactive in a way that imperative programs are not. The operations in a dataflow graph fire in response to receiving input.
-
In an imperative program, coordination between a method and its caller happens by returning a single value to the caller. In a dataflow program, an operation can emit multiple values to multiple operations.
Dataflow in Rama
So in dataflow programs, you construct a computation graph where each node receives input and emits output values to other nodes. How does this all work in Rama? How do you specify the structure of the dataflow graph, and how do you specify the operations for each node?
These two questions are intertwined, but let’s start by focusing on how to specify the graph structure. (As we specify the graph, we’ll also specify the nodes' operations by using Rama’s built-in operations, but soon you’ll see how to write operations of your own.)
The examples we’ll look at will be very simple. They’ll be disconnected from modules and ETLs so that you can focus just on the dataflow machinery. The following code can be run from any Java process just with Rama on the classpath as a library. You can also try these examples in a Groovy shell – Groovy is similar enough to Java that these examples can be run in Groovy without changes. As a reminder, to launch a Groovy shell from rama-examples run mvn compile gplus:shell.
Here’s the first example:
public static void singleNode() {
Block.each(Ops.PRINTLN, 10).execute();
}To run this in a Groovy shell, enter the following:
groovy:000> import com.rpl.rama.Block;
groovy:000> import com.rpl.rama.ops.Ops;
groovy:000> Block.each(Ops.PRINTLN, 10).execute();We create a dataflow graph consisting of one node. Then we execute it, printing the number 10.
How does this work? Block.each() establishes a new dataflow graph and creates
a single node in it; in general, each() will append a node. You can think of
it as meaning, "Each time this node receives input, execute the given operation
with the given arguments." In this case, the given operation is Ops.PRINTLN, and
the argument is 10.

The Rama API follows the builder pattern, so that when you call the .each()
method it returns a value that you can use to chain methods and further build up
the dataflow graph, or (as in the case of this example) call the execute()
method.
You can think of execute() as "send an input to this dataflow graph". The
input is empty, but nevertheless the behavior of the dataflow graph is "execute
the given operation on every input". Therefore, the Ops.PRINTLN operation runs
and prints 10.
Variable scope
Let’s look at another example. This example will help you understand how the Rama API connects nodes, as well as how Rama handles scope:
Block.each(Ops.IDENTITY, "a").out("*x")
.each(Ops.PRINTLN, "*x")
.execute();In this example, we create a dataflow graph with multiple nodes. Each call to
each() creates a node, just as before, and the call to out() creates a node
too. If you were to walk through the graph’s construction step by step, this is
what happens:
-
Create a node that performs the
Ops.IDENTITYoperation with the argument"a"for each input. -
Connect this node with a node for
out("*x")(You’ll see whatout("*x")does in a second). -
Create another node that performs the operation
Ops.PRINTLN. Whenout("*x")emits a value, the node foreach(Ops.PRINTLN, "*x")receives it as input.
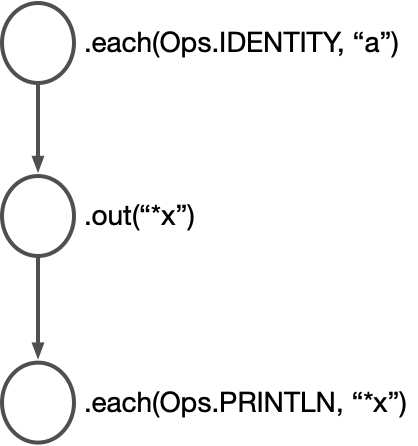
In general, as you chain calls to each and out, you construct a linear
dataflow graph. The output of one node becomes the input to the next.
There’s something interesting happening here: the first node emits the string
"a", and the third node is able to read this value. This is possible because
Rama’s dataflow nodes also receive a scope as an implicit input value,
and out updates this scope. When each(Ops.IDENTITY, "a") emits the string
"a", the node out("*x") receives "a" as input along with an empty scope.
out updates the scope, assigning "a" to the identifier "*x". We call these
scoped bindings vars; "*x" refers to a var.
Thus, when the next node — each(Ops.PRINTLN, "*x") — receives its input, the
string "a" is included, bound to the identifier "*x" in the input’s scope.
When you include a string with a "*" or "$$" prefix in the argument list to
each, Rama’s behavior is to look up the corresponding value in the scope and
use that when performing the given operation. If you need to pass in a literal
string containing that prefix as an argument, you do that by constructing a new
Constant, like new Constant("*x").
With this in mind, let’s look at an example that has more nodes but that employs only the concepts you’ve learned so far:
Block.each(Ops.IDENTITY, "a").out("*x")
.each(Ops.IDENTITY, "b").out("*y")
.each(Ops.TO_STRING, "*x", "*y", 1, "!", 2).out("*z")
.each(Ops.PRINTLN, "*z")
.execute();This graph incrementally builds up values in the scope, and then creates a
combined value with Ops.TO_STRING that’s used to print the value "ab1!2". You’ll be doing a
lot of this as you work with Rama.
Performance
Rama compiles these dataflow graphs to very efficient bytecode. For example, variables used in dataflow code become actual variables in bytecode, even though they aren’t defined using traditional Java syntax. Likewise, more advanced dataflow constructs like loops and conditionals also compile to very efficient bytecode.
A quick aside on execute()
In real production code, you won’t use the execute() method. We’re only using
it here to synthetically send input events to a dataflow graph’s root node. In
real code, you’ll source data from data depots, like we did in previous
examples:
public class SimpleWordCountModule implements RamaModule {
@Override
public void define(Setup setup, Topologies topologies) {
setup.declareDepot("*wordDepot", Depot.random());
StreamTopology s = topologies.stream("wordCountStream");
s.pstate("$$wordCounts", PState.mapSchema(Object.class, Object.class));
s.source("*wordDepot").out("*token")
.hashPartition("$$wordCounts", "*token")
.compoundAgg("$$wordCounts", CompoundAgg.map("*token", Agg.count()));
}
}Here, the dataflow graph’s root is a node created by s.source("*wordDepot").
This node works by continually reading records from the "*wordDepot" depot and
emitting them.
With that explained let’s return to constructing dataflow graphs:
Branching dataflow graphs
It’s possible to create branching dataflow graphs, where a node A emits to nodes B and C, and B and C’s operations execute independently of each other. It’s also possible to unify nodes, so that two or more nodes emit to the same node.
Doing this in Rama’s dataflow API is a little interesting because you’re building a 2-dimensional structure (the graph) using a 1-dimensional tool (a sequence of dataflow API calls). Here’s a bare bones example:
public static class Brancher implements RamaOperation0 {
@Override
public void invoke(OutputCollector collector) {
collector.emitStream("pizzaOrders", 1);
collector.emitStream("saladOrders", 10);
collector.emitStream("saladOrders", 11);
}
}
public static void unifyExample() {
Block.each(new Brancher()).outStream("pizzaOrders", "pizzaAnchor1", "*pizzaOrderSize")
.outStream("saladOrders", "saladAnchor1", "*saladOrderSize")
.each(Ops.DEC, "*saladOrderSize").out("*orderSize")
.anchor("saladAnchor2")
.hook("pizzaAnchor1")
.each(Ops.INC, "*pizzaOrderSize").out("*orderSize")
.anchor("pizzaAnchor2")
.unify("pizzaAnchor2", "saladAnchor2")
.each(Ops.PRINTLN, "*orderSize")
.execute();
}This constructs a graph that looks like this:
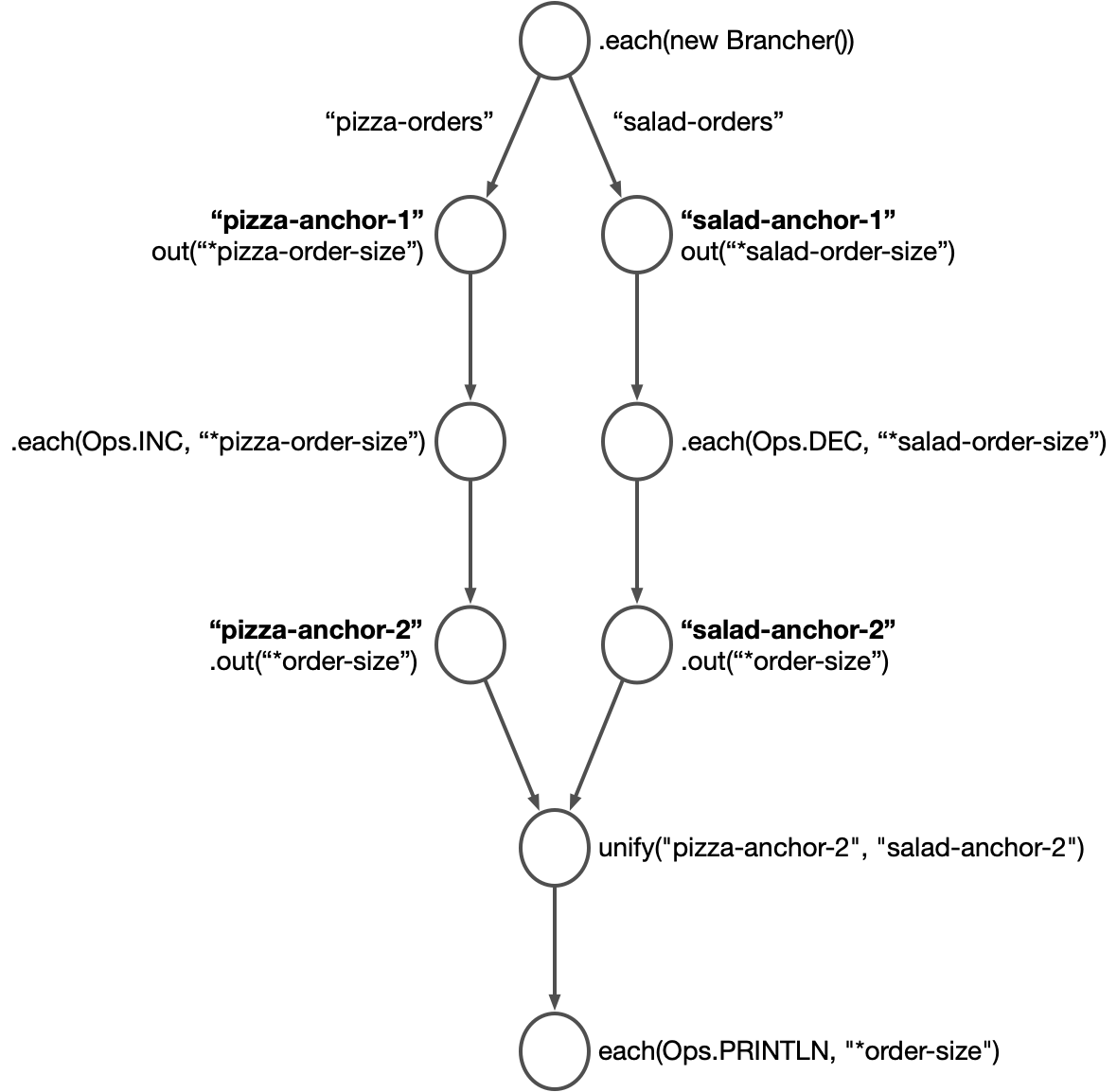
Output streams, hooks, anchors, and unify
Let’s walk through code graph line by line to understand what’s happening.
First, we create an operation, Brancher (the next section goes into detail
about how to create operations).
The Brancher operation uses its collector argument to emit to two separate
streams, "pizzaOrders" and "saladOrders". This is how you emit to
multiple outputs; you don’t emit directly to another node as you don’t know what the
other nodes are. Instead, you emit values by placing them in named streams, which
can be thought of as channels or sockets, and which can be visualized as the
arcs between dataflow nodes.
In fact, every other graph we’ve constructed so far has emitted values to
streams and not directly to other nodes. We just haven’t named those streams,
because we haven’t needed to. In the absence of constructs like emitStream()
which allow you to specify a stream, nodes emit to what is called the default
output stream. As you add nodes, they implicitly take the most recently
constructed output stream as their input. Let’s look at a previous example:
Block.each(Ops.IDENTITY, "a").out("*x").each(Ops.IDENTITY, "a") creates a node that emits the value "a", but
doesn’t specify which stream to emit to, so it emits to the default output
stream. The method call .out("*x") is chained to the return value of each,
and the Rama API interprets this as hooking up the default output stream of each to
out:
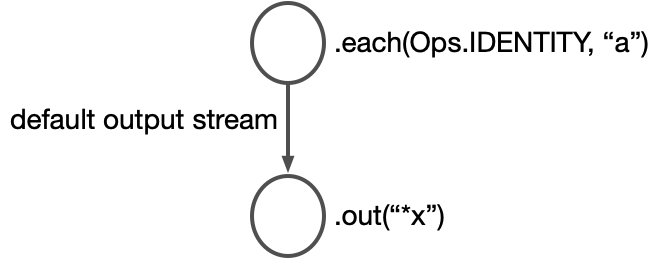
Back to our branching example. The method call .each(new Brancher()) creates a
node whose operation is to emit values to two streams, "pizzaOrders" and
"saladOrders". Next we need to create nodes to receive those values as
inputs, and that’s done with the calls to .outStream("pizzaOrders",
"pizzaAnchor1", "*pizzaOrderSize") and .outStream("saladOrders",
"saladAnchor1", "*saladOrderSize"). Like the out method, outStream
creates a node that creates a new scope binding; one of the nodes creates a
binding to "*pizzaOrderSize" and the other creates a binding to
"*saladOrderSize". .outStream() differs from .out() in that you also
specify which stream is the input, and you specify the name for the node that
gets created. In .outStream("pizzaOrders", "pizzaAnchor1",
"*pizzaOrderSize"), "pizzaOrders" is the input stream and
"pizzaAnchor1" is the name for the node that’s created by this method call.
In Rama, names for nodes are called anchors. You name nodes when constructing
graphs with branches in order to specify which branch to add more streams and
nodes to. The above example branches into two streams, each connected to an
outStream node. The line .each(Ops.DEC, "*saladOrderSize") builds off of
the outStream node that precedes it – in this case, saladAnchor1
What if you want to build off pizzaAnchor1? This is where you have to deal
with the fact that the dataflow graph is two-dimensional, but our code is one-dimensional.
You use the hook method call to indicate that you want to start building off a
different node. Here, we use hook("pizzaAnchor1") to indicate that the
subgraph that follows should be attached to the node pizzaAnchor1.
Unifying dataflow branches
You can unify dataflow branches so they emit to the same node. There isn’t any requirement for you to unify output streams like this – it’s really up to you and what your application needs. But when you do need it, here’s how it works:
First, in the example we’ve been looking at each dataflow branch includes the method call out("*orderSize"),
creating out nodes.
Next, we name each of nodes branches with the anchor() method call. Whereas
the outStream() method lets you provide an anchor name for the node it
creates, the anchor() method call allows you to attach an anchor to the
node right before the call. Thus, the node for out("*orderSize") in the "saladAnchor1" branch
is named "saladAnchor2", and likewise for the pizza branch.
After that, we use unify("pizzaAnchor2", "saladAnchor2") to create a new
node, with the nodes referenced as inputs. Each time either of those nodes emits
a value, then the unify node will receive it as input. It doesn’t perform any
further operations and connects to the node for each(Ops.PRINTLN, "*orderSize").
Note that the var "*orderSize" was defined in each of the unified
branches. A var is considered in scope after a unify if it
satisfies one of two conditions:
-
It was in scope before the branch point of the unify tree
-
It’s defined on all branches of the unify tree
"*orderSize" is defined in each branch of the unify tree, so it’s available
after the unify node.
Conditionals
You can add conditionals to your dataflow graph, so that when the conditional is true a provided sub-graph receives input. The following example shows how you might check whether two numbers are equal:
public static void simpleConditionalExample() {
Block.each(Ops.EQUAL, 1, 2).out("*condition")
.ifTrue("*condition",
Block.each(Ops.PRINTLN, "math is dead!"))
.each(Ops.PRINTLN, "Conditional complete")
.execute();
}This creates a graph that looks like this:
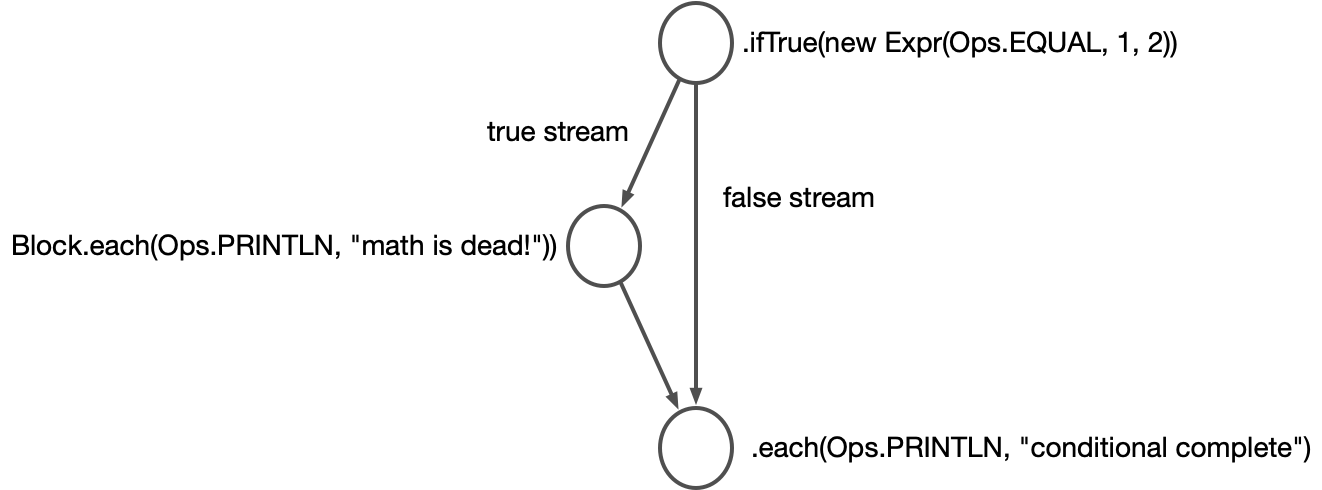
The method ifTrue here takes two arguments, a condition value and a block. It creates a
new node in the dataflow graph with two output streams; the node emits to the
false stream when the condition value is null or false, and true otherwise. The provided
block receives input from the true stream.
Note that there’s an implicit unification: both branches of the condition end up emitting to the same node.
Usually you wouldn’t bind an explicit var for the condition value, but you would nest an expression like so:
public static void simpleConditionalExample() {
Block.ifTrue(new Expr(Ops.EQUAL, 1, 2),
Block.each(Ops.PRINTLN, "math is dead!"))
.each(Ops.PRINTLN, "Conditional complete")
.execute();
}This is equivalent to the previous example, and in fact behind the scenes compiles to the previous example. Expr can be used anywhere input arguments are taken and are useful for making the code more concise.
What if you want to include an else clause to a condition? To do that, you just pass in another block as the third argument to ifTrue:
public static void twoConditionalsExample() {
Block.ifTrue(new Expr(Ops.EQUAL, 1, 2),
Block.each(Ops.PRINTLN, "math is dead!"),
Block.each(Ops.PRINTLN, "math is alive!"))
.each(Ops.PRINTLN, "conditional complete")
.execute();
}This produces a graph like this:
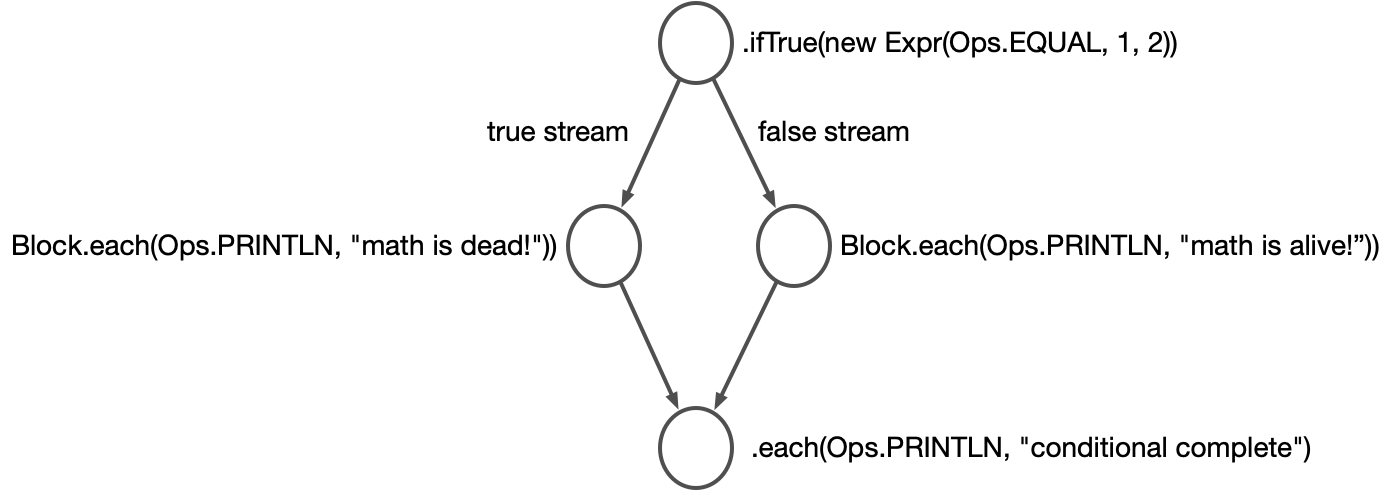
Again, there’s an implicit unification here. That means it’s possible to introduce new var bindings, but for those bindings to be accessible post-unification, they must be present in each branch. So this code would fail to compile:
public static void invalidUnificationExample() {
Block.ifTrue(new Expr(Ops.EQUAL, 1, 2),
Block.each(Ops.IDENTITY, 1).out("*a"),
Block.each(Ops.IDENTITY, 2).out("*b"))
.each(Ops.PRINTLN, "*a")
.execute();
}But this code compiles fine because "*a" is available on both branches of the conditional:
public static void validUnificationExample() {
Block.ifTrue(new Expr(Ops.EQUAL, 1, 2),
Block.each(Ops.IDENTITY, 1).out("*a"),
Block.each(Ops.IDENTITY, 2).out("*a"))
.each(Ops.PRINTLN, "*a")
.execute();
}Rama checks the scope of all vars when compiling a Block and will never execute code that has an invalid var reference.
Writing custom operations
Now that you’ve looked at how to construct a dataflow graph, let’s have a look at
how to write custom operations for nodes. There are two different kinds of
implementations for operations: RamaFunction and RamaOperation. Let’s look
at an example of a RamaFunction first:
public static class AddTen implements RamaFunction1<Integer, Integer> {
@Override
public Integer invoke(Integer l) {
return l + 10;
}
}
public static void ramaFunctionExample() {
Block.each(new AddTen(), 1).out("*numberPlusTen")
.each(Ops.PRINTLN, "*numberPlusTen")
.execute()
}Of note:
-
AddTenis a public static class with a single public method,invoke. -
It extends
RamaFunction1. The 1 designates how many arguments this operation takes; there’s alsoRamaFunction0all the way throughRamaFunction8. -
eachwill callinvoke, passing in whatever additional arguments you pass toeach -
invokewillreturna value, and that value is emitted to the default output stream.
RamaFunction is the simpler, stripped-down implementation of operations. When
you implement a RamaFunction, your invoke method should always return a
value. And whereas RamaOperation implementations can emit multiple times and
to multiple streams, a RamaFunction can only emit once. You should prefer a
RamaFunction where possible because it’s more efficient. It’s also more
concise in that you don’t need to use an OutputCollector.
A RamaOperation is more general than a RamaFunction, capable of emitting multiple times, doing work between emits, emitting to multiple streams, and emitting multiple fields in a single emit. Here’s an example demonstrating all of this:
public static class MyOperation implements RamaOperation0 {
@Override
public void invoke(OutputCollector collector) {
int x = 1;
collector.emitStream("streamA", x);
int y = x + 2;
collector.emit(x, y, "s");
collector.emitStream("streamB");
}
}This function could be invoked in dataflow code like this:
Block.each(new MyOperation()).outStream("streamA", "anchorA", "*v1")
.outStream("streamB", "anchorB")
.out("*a", "*b", "*c")Here, MyOperation is implementing RamaOperation0, indicating it takes zero
arguments. And yet, invoke takes an argument, OutputCollector collector.
This is the object you use to emit arbitrary values to arbitrary streams, and you
can see in the example we do indeed emit to three streams, taking in various amounts of values as input. When invoking a RamaOperation via the dataflow API, it’s important when using out or outStream you capture exactly the number of values
emitted. Just like how you must call methods in Java with the correct number of input arguments, you must capture the outputs of Rama with the correct number of output bindings.
When a RamaOperation emits, the code connected to the corresponding outStream or out is executed immediately. Control flow returns back into the RamaOperation only when that downstream code finishes executing.
Another way to write custom operations is to use lambdas. You could rewrite the
ramaFunctionExample above like this:
public static void ramaFunctionExample() {
Block.each((Integer l) -> l + 10, 1).out("*numberPlusTen")
.each(Ops.PRINTLN, "*numberPlusTen")
.execute()
}Yet another approach is to use method references:
public static void ramaFunctionExample() {
Block.each(Math::abs, 1.2).out("*absoluteValue")
.each(Ops.PRINTLN, "*absoluteValue")
.execute()
}Method references are nice because they can be used from other Java code as well
as directly in topologies. Lambdas and method references are less verbose than a RamaFunction
and are generally preferred.
Immutable scope and shadowing
Because scope bindings can be emitted to multiple nodes, you might be wondering if it’s possible for one node to change another node’s bindings.
Good news: scope bindings are immutable. When a node emits a scope, nothing can change it between the time it’s emitted and the time it’s received as input by its child nodes. Even if you create a new binding with the same name, that creates a new immutable scope and doesn’t affect other scopes. This example demonstrates this idea:
public static class Person {
public String name;
public Person(String name) {
this.name = name;
}
}
public static class MultiOut implements RamaOperation0 {
@Override
public void invoke(OutputCollector collector) {
collector.emitStream("stream1");
collector.emitStream("stream2");
}
}
public static void shadowExample() {
Block.each(Ops.IDENTITY, new Person("Megan")).out("*person")
.each(new MultiOut()).outStream("stream1", "stream1Anchor")
.outStream("stream2", "stream2Anchor")
.each(Ops.IDENTITY, new Person("John")).out("*person")
.hook("stream1Anchor")
.each((Person person) -> person.name).out("*personName")
.each(Ops.PRINTLN, "*personName")
.execute();
}
public static void shadowMutationExample() {
Block.each(Ops.IDENTITY, new Person("Megan")).out("*person")
.each(new MultiOut()).outStream("stream1", "stream1Anchor")
.outStream("stream2", "stream2Anchor")
.each((Person person) -> {
person.name = "John";
return null;
})
.hook("stream1Anchor")
.each((Person person) -> person.name).out("*name")
.each(Ops.PRINTLN, "*name")
.execute();
}The MultiOut operation emits to two separate streams. It also implicitly emits its scope, which includes a binding for "*person".
In shadowExample, the "stream2" branch creates a new Person and binds that
object to the name "*person". This will never affect the binding in
"stream1"; "stream1" will always print "Megan".
In shadowMutationExample, however, the "stream2" branch actually mutates the
shared object that happens to be bound to *person in both branches. In this
case, it’s possible for "stream1" to print "John", depending on the order in
which the branches are executed. In this case, because MultiOut emits to "stream1" first, it will print "Megan". If MultiOut were changed to emit to "stream2" first, it would print "John".
Looping
Rama’s dataflow API also includes a looping construct. In fact, because Rama’s dataflow API has both condition and looping constructs, it is Turing-complete. Here’s an example of looping in Rama:
public static void loopExample() {
Block.loopWithVars(LoopVars.var("*i", 0),
Block.ifTrue(new Expr(Ops.NOT_EQUAL, "*i", 5),
Block.emitLoop("*i")
.each(Ops.PRINTLN, "Variable *i is not 5 yet")
.continueLoop(new Expr(Ops.INC, "*i")))).out("*loopValue")
.each(Ops.PRINTLN, "Emitted:", "*loopValue")
.execute();
}This prints out:
Emitted: 0
Variable *i is not 5 yet
Emitted: 1
Variable *i is not 5 yet
Emitted: 2
Variable *i is not 5 yet
Emitted: 3
Variable *i is not 5 yet
Emitted: 4
Variable *i is not 5 yetHere is the graph it produces:
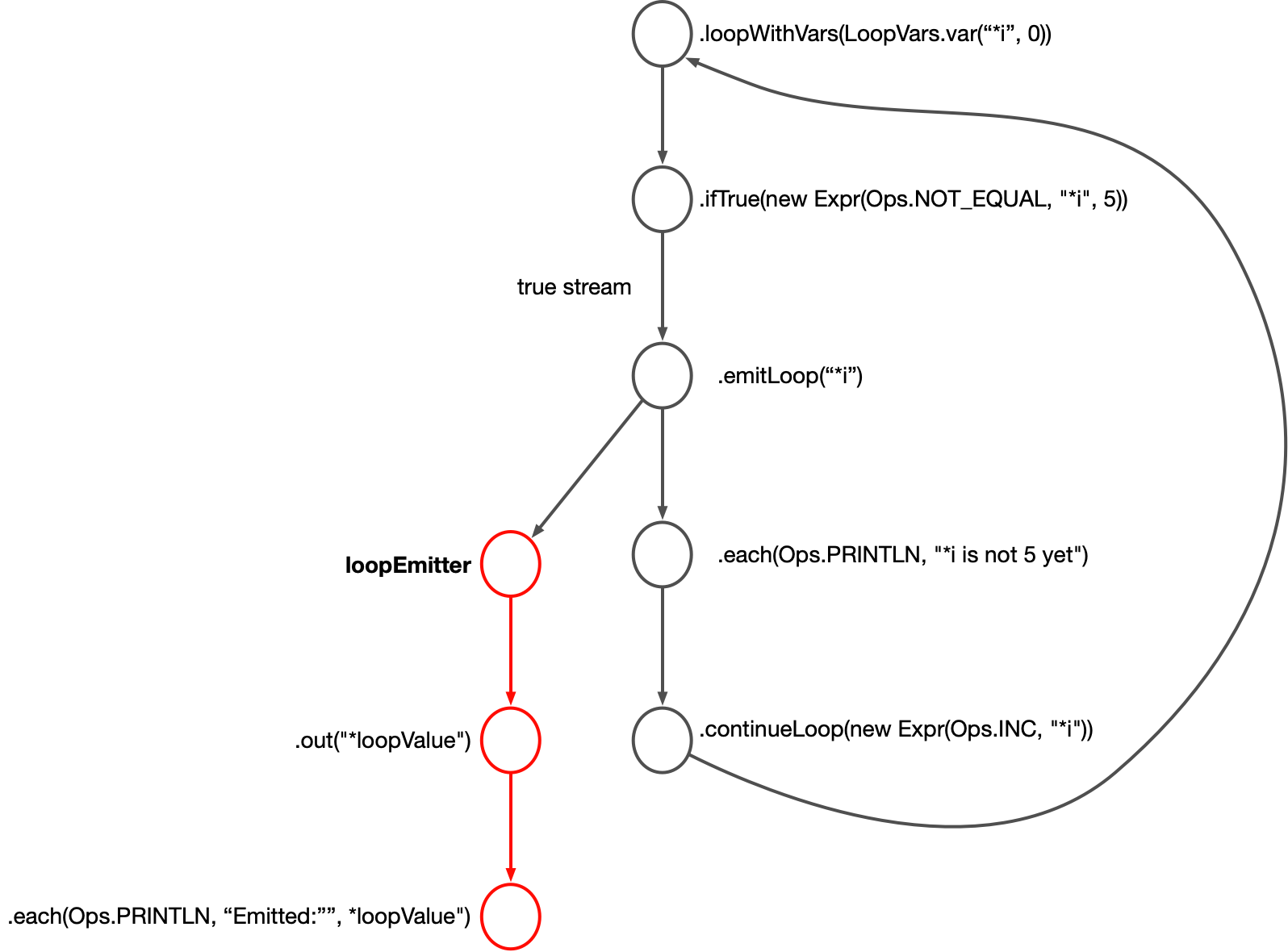
This looks somewhat similar to the conditional graph you just saw. loopWithVars
creates a node, which we’ll call the loop root. When it emits, its scope
includes an initial binding for the var "*i". It emits to an ifTrue node which checks a base
condition for whether to execute an iteration of the loop.
The loop’s control flow is implemented with continueLoop and emitLoop.
continueLoop creates a new node that emits a value to the node loop root. The
loop root uses this to kick off a new loop iteration, binding "*i" to the
value it receives as input from continueLoop. Thus the initial execution of
the loop has "*i" bound to the number 0, and the next execution has "*i" bound
to 1 and so on until the value of "*i" is 5.
When emitLoop is called, flow control immediately goes to the out("*loopValue") node and what follows from that. When that branch of code finishes, flow control goes back to the next node after emitLoop. Think of what comes after the loop as a function that emitLoop calls (this is formally known as the loop’s "continuation"). If you have multiple emitLoop nodes in a loop, they will all emit to the same loopEmitter node, and whatever loopEmitter receives as input it then executes the following node.
The way to execute another iteration of a loop is to call continueLoop with the new values for the loop vars. This example executes the loop body five times. If continueLoop is not called, execution of the loop stops.
Note that these semantics are different than what you’re used to from looping constructs in languages like Java, where control flow moves past a loop once the loop finishes. In Rama, control flow moves past the loop only when emitLoop is called and this is before the loop has finished executing. A loop finishing in Rama does not move control flow past the loop.
Looping without vars
There’s another dataflow method loop that works exactly like loopWithVars but doesn’t require a var declaration. When using this construct you would generally determine whether to continue looping based on some mutable state bound before the loop. Here’s an example:
public static void loopExample() {
Block.each((RamaFunction0) ArrayList::new).out("*list")
.loop(
Block.each(Ops.SIZE, "*list").out("*size")
.ifTrue(new Expr(Ops.EQUAL, "*size", 3),
Block.emitLoop(),
Block.each((List l) -> l.add("iter"), "*list")
.continueLoop()))
.each(Ops.PRINTLN, "Result:", "*list")
.execute();
}This prints:
Result: #object[java.util.ArrayList 0x68b4eba7 [iter, iter, iter]]Note here there’s no out attached to the loop call – Rama inserts that implicitly when it’s not provided.
Summary
In this section, you learned the basics of dataflow programming. Rama’s dataflow API is expressive and flexible, giving you precise control over how data is processed and how logic branches and merges.
There are more dataflow features in the Rama API that weren’t covered in this section. These include batch computation (e.g. joins, aggregation) and facilities for separating dataflow code into reusable chunks. These features and more are covered in Intermediate dataflow programming.