Backups
Rama can be configured to back up all module state to an external storage service. The backup provider is pluggable, and an open-source implementation is provided for Amazon S3. Restoring a module to a previous state is a simple one-line command. This page covers:
-
How backups work
-
How to configure backups
-
Viewing available backups
-
Restoring a backup
-
Setting policies to delete old backups
-
Implementing a new backup provider
-
Backing up cluster when using free license
How backups work
When backups are configured, Rama backs up all module state:
-
Depots
-
PStates
-
Topology progress
-
Module jar
-
Config overrides
-
Dynamic options
Backups are stored in an external storage service (such as Amazon S3). The backup provider implements a filesystem-like interface, explained below. Rama stores files for module objects in that store along with manifests listing what files are needed to restore each task’s state for all objects and metadata.
Backups are incremental, so when a module is backed up it only backs up new files that have accumulated since the last backup. This includes log segments for depots, SSTs and write-ahead logs for PStates, and miscellaneous files with topology progress information.
Additionally, backups are done in a way to maintain Rama’s strong atomicity guarantees. All partitions for a microbatch PState are backed up at the same commit ID, and stream topology PState partitions are backed up at their value at the same point in time. A microbatch topology is an atomic cross-partition transaction for all changes to all PStates on all tasks, and a stream topology event is an atomic transaction for all PState changes on that task in that event. Backups are careful to ensure these properties are maintained.
Lastly, backups guarantee that depots contain all entries that may have affected any PStates.
Configuring backups
Backups are configured by putting a jar for the backup provider implementation on the classpath of the Conductor, Supervisors, and workers, and then by telling the cluster which backup provider to use and with what parameters.
The jar for the backup provider implementation should be placed in the lib/ directory on the Conductor and all Supervisors. The Conductor, Supervisor, and module workers won’t pick up the jar into their classpath until they’re restarted. The Conductor and Supervisor processes can be restarted directly, and the easiest way to restart all workers is to do a module update.
The backup provider is configured by adding the backup.provider config to the rama.yaml on the Conductor. For example, you could configure the open-source AWS S3 backup provider like so:
backup.provider: "com.rpl.rama.backup.s3.S3BackupProvider my-bucket-on-s3"The config for backup.provider is the name of the class implementing the backup provider interface along with an argument separated by a space. The Conductor process must be restarted to pick up the new config.
Multiple Rama clusters should not use the same backup provider config. If they do, there’s risk of one cluster doing GC of files for an in-progress backup from the other cluster, causing the backup to be corrupted. When a backup provider config is unique to a cluster, backups and GC are coordinated so that can’t happen.
Backups can either be triggered manually from the Rama CLI, or a module can be configured to back up at a regular interval. Either way, the backup is incremental and only new state is written into the backup provider.
Triggering an immediate backup is done with the CLI like so:
rama backup --action backup --module com.mycompany.MyModuleRegular backups are configured by setting the backup.period.seconds dynamic option for the module.
Viewing available backups
The easiest way to view all backups available is through the Cluster UI on the main module page. The section looks like the following:
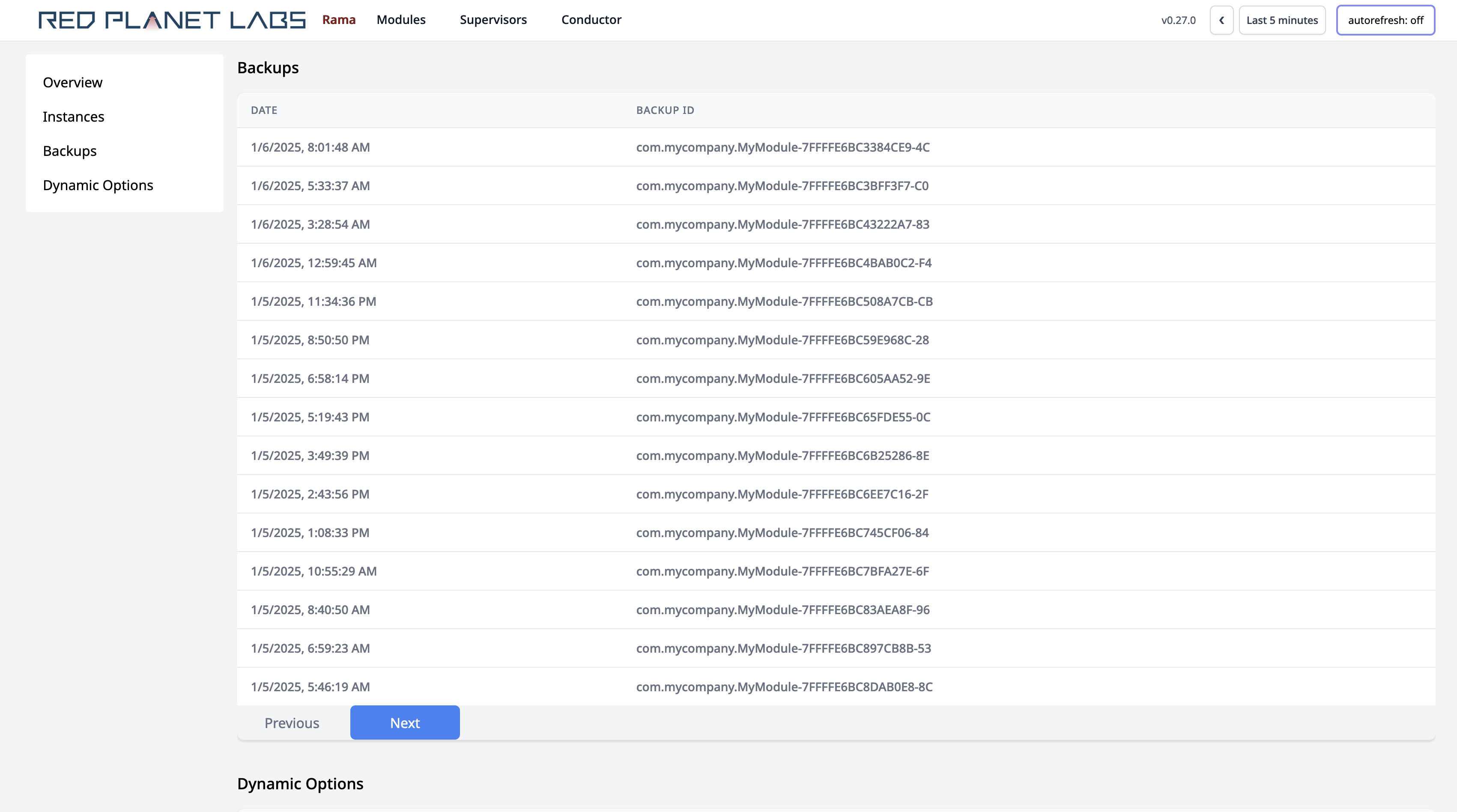
Each backup is identified by a "backup ID", which is used to restore a module to that particular backup. You can view information about what was in the module for a particular backup (e.g. depots, PStates, topologies) using the CLI "info" command, like so:
rama backup --action info --backupId com.mycompany.MyModule-00000193E038B5F8-DEAs an alternative to the Cluster UI, you can also view all backups through the CLI like so:
rama backup --action list --module com.mycompany.MyModuleThe CLI is also paginated, and each page prints a token to use to fetch the next page. Here’s an example of fetching the next page of backups:
rama backup --action list --module com.mycompany.MyModule --pageToken JMN2983AJDRestoring a backup
You can restore a module to a backup using the CLI "restore" command. If the module is currently running, the command only needs the backup ID, like so:
rama backup --action restore --backupId com.mycompany.MyModule-00000193E038B5F8-DEIf the module is not currently running, the command needs to know the parallelism and replication settings desired for the module. They are specified just like module launch, like so:
rama backup --action restore --backupId com.mycompany.MyModule-00000193E038B5F8-DE --threads 32 --workers 10 --replicationFactor 2Just like module launch, --replicationFactor is optional and defaults to one. The number of tasks is not specified because that’s part of the backup itself.
Note that a restore in non-reversible, so if you might need to revert it you should back up the module first.
A restore is only permitted if the restored version meets all dependencies required by other modules. For example, if another module depends on PState $$p of the restoring module, the restore will be rejected if the chosen backup does not have that PState.
Effect of restoring on module dependencies
Topologies carefully track which offsets they’ve processed from depots. If a topology subscribes to a depot on another module and that module is restored to a prior backup, the offsets it tracks are no longer valid and the topology needs to recalibrate. For example, suppose topology "core" in Module B subscribes to depot "*depot" in Module A and has currently processed up to offset 205. If Module A is restored to a prior version where the depot contained entries up to offset 107, then any new data appended after the restore will start at offset 107. So the "core" topology needs to reset its "processed offset" to 107 to ensure it processes that new data.
Rama handles this recalibration automatically for both cases of topologies depending on depots in a restored module and for topologies in a restored module depending on depots in other modules. It does this by tracking metadata about when a module was restored and checking whether that metadata is inconsistent with expectations when fetching data. The recalibration generally happens within a few seconds of a module completing its restore.
Setting policies to delete old backups
Rama can be configured delete old backups in order to reduce the amount of storage space used in the backup provider. Each backup consists of manifests for the files used by each object on each task. Files can be shared across multiple manifests, which is how Rama’s backups are incremental. Backup GC (garbage collection) works by deleting manifests according to configured policy and then deleting files that aren’t reachable from any manifest.
The dynamic option backup.gc.period.seconds specifies how often backup GC should run. backup.max.age.hours specifies how long to keep each backup, and backup.min.backups.to.keep specifies the number of backups to keep irrespective of age.
Implementing a new backup provider
A new backup provider must implement the BackupProvider interface which consists of filesystem-like operations. The operations all return their results asynchronously via CompletableFuture objects.
Backup provider operations are all executed on a dedicated thread that’s separate from task threads running work for modules, so you don’t need to worry about backup operations interfering with a module’s regular work. It’s still important for them to execute as asynchronously as possible so that multiple task threads can execute backup operations in parallel.
See the S3 backup provider repository for a reference implementation of making a backup provider.
Backing up cluster when using free license
Rama’s first-class backups feature that does incremental backups without interfering with module operation requires a paid license. If you’re using the free version of Rama, you can still back up your cluster, but it’s a manual process that requires taking some downtime.
The steps to back up manually are:
-
Run
rama shutdownClustercommand on the Conductor -
Wait until conductor state in the UI is
[:cluster-shutdown-complete] -
Kill Conductor and Supervisor processes as well as any process supervision for them
-
Make a snapshot of Zookeeper
-
Once no processes are running, all state for Rama daemons in the configured data dir can be copied to the external store of your choice
To restore the cluster to a previous backup:
-
Restore the Zookeeper snapshot
-
Restore the state of the Conductor and all Supervisor data dirs
-
Start the Conductor and Supervisor processes
-
The cluster will automatically start up all modules and continue operating from the state of the backup
Note that for this process to work, the cluster must be on same Rama version as when it was backed up.
Conclusion
Rama’s backup implementation is easy to configure, efficient, and comprehensive. Backups provide a layer of protection against catastrophic error, whether from a natural disaster or human error. Backups in Rama are another way that Rama simplifies operations – since Rama can build a backend with diverse computation and storage needs on its own, having backups built-in greatly reduces the operational work that would otherwise go into backing up many individual systems.